Appearance
题目
某计算机的主存地址空间大小为 256MB,按字节编址。指令 Cache 和数据 Cache 分离,均有 8 个 Cache 行,每个 Cache 行大小为 64B,数据 Cache 采用直接映射方式。现有两个功能相同的程序 A 和 B,其伪代码如下所示:
c
// 程序 A
int a[256][256];
.....
int sum_array1()
{
int i, j, sum=0;
for (i=0; i<256; i++)
for (j=0; j<256; j++)
sum += a[i][j];
return sum;
}c
// 程序 B
int a[256][256];
.....
int sum_array2()
{
int i, j, sum=0;
for (j=0; j<256; j++)
for (i=0; i<256; i++)
sum += a[i][j];
return sum;
}假定 int 类型数据用 32 位补码表示,程序编译时 i,j,sum 均分配在寄存器中,数组 a 按行优先方式存放,其首地址为 320(十进制数)。请回答下列问题,要求说明理由或给出计算过程。
(1) 若不考虑用于 cache 一致性维护和替换算法的控制位,则数据 Cache 的总容量为多少?
(2) 数组元素 a[0][31] 和 a[1][1] 各自所在的主存块对应的 Cache 行号分别是多少(Cache 行号从 0 开始)?
(3) 程序 A 和 B 的数据访问命中率各是多少?哪个程序的执行时间更短?
解析
本题是一道经典的"直接映射 Cache + 局部性"综合题。三问层层推进:
- 先把 Cache 行的物理结构 算清楚(每行除了数据,还要存 Tag 和有效位);
- 再用 直接映射的地址划分 找出具体元素在哪一行;
- 最后通过 行优先存放 vs 行优先 / 列优先访问 的匹配关系,看局部性能否被 Cache 利用。
行优先访问 → Cache 友好;列优先访问 → 跨步太大反复换出,是本题最关键的洞察。
(1) 数据 Cache 的总容量 [3 分]
Step 1. 拆解主存地址。
主存空间 256MB,按字节编址 → 地址总长度:
每行 64B → 块内偏移:
直接映射,共 8 行 → 行索引:
剩下的高位是 Tag:
Step 2. 算每行的标记开销。
题目要求"不考虑一致性维护位(脏位等)和替换算法控制位",所以每行只保留 有效位(1 bit)+ Tag(19 bits):
| 字段 | 有效位 | Tag | 数据 |
|---|---|---|---|
| 位数 | 1 | 19 |
每行总比特数 = bits。
Step 3. 算 Cache 总容量。
易错点: 题目说"总容量"不仅指数据区。一定要把 Tag 和有效位都算进去;只算 8×64 = 512B 是只算了"可装数据",会丢分。
(2) a[0][31] 与 a[1][1] 的 Cache 行号 [3 分]
直接映射的行号公式:
数组按行优先存放,每个 int = 4B,首地址 320。元素 a[i][j] 的字节地址:
计算 a[0][31]:
计算 a[1][1]:
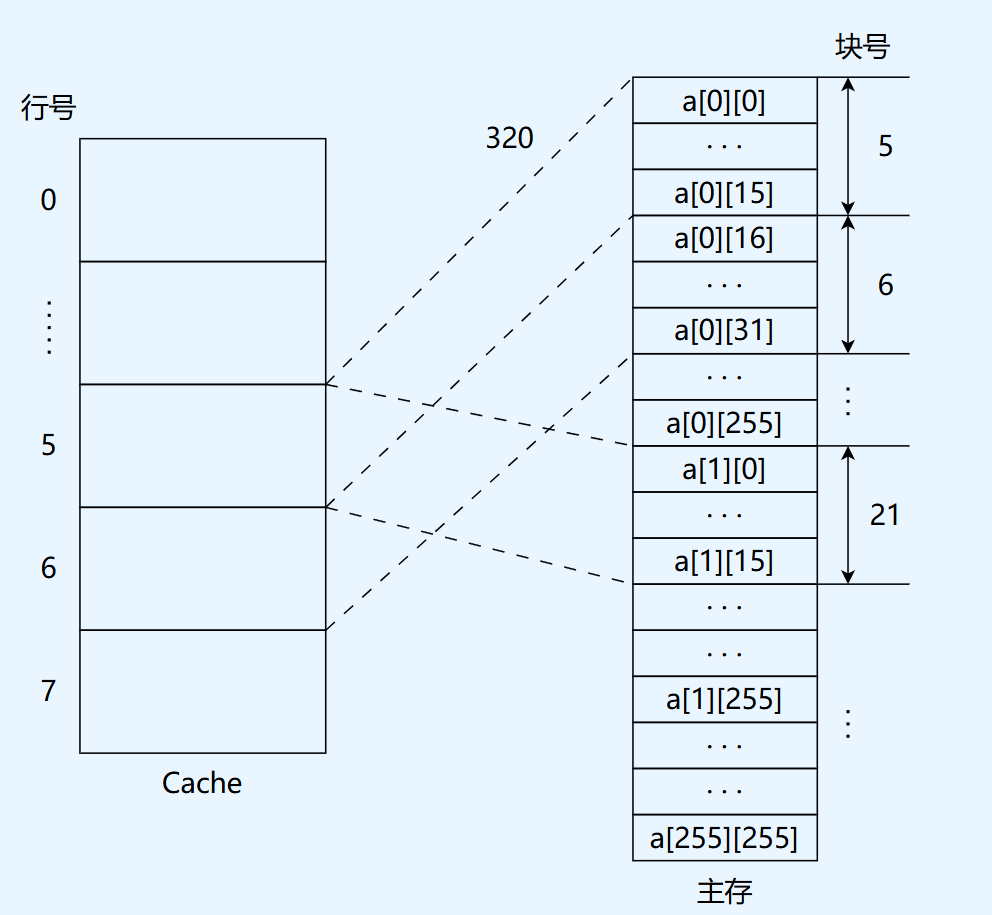
易错点: 不要忘记首地址 320 不是 64 的倍数,所以
a[0][0]不落在 Cache 行 0 的第一个字节上。先做绝对地址计算,再除以 64 取整,再 mod 8。
(3) 程序 A、B 的命中率与执行时间对比 [5 分]
铺垫:算清楚数组占多少块。
数组总大小:
占用主存块数:
总访问次数: 次。
程序 A:行优先访问行优先存放 → 局部性极佳。
每个字块容纳 16 个 int()。按行扫到 a[i][0] 时块未在 Cache,首访 miss;随后访问 a[i][1]…a[i][15] 都在同一块内,全部 hit。每访问 16 次产生 1 次 miss:
程序 B:列优先访问行优先存放 → 局部性被破坏。
按列扫,从 a[0][j] 跳到 a[1][j] 要跨 256 个 int = 1024B。
- 数组每行 = ;
- Cache 总数据容量 = ;
数组一行就是 Cache 数据容量的 2 倍,所以 a[0][j]、a[2][j]、a[4][j]...这些"按列跳"的元素分别落入不同的主存块,且映射到的 Cache 行存在反复冲突替换——每访问 1 个新元素就把上一个换出去:
执行时间对比。
Cache 命中(约 1 个时钟周期)远快于主存访问(数十个时钟周期)。程序 A 几乎全部命中,程序 B 全部 miss。结论:程序 A 的执行时间远短于程序 B。
易错点 1(命中率公式): 。不要把"每块 1 次 miss"误当成"每行 1 次 miss"——主存块和 Cache 行虽然大小相同,但主存块远多于 Cache 行。
易错点 2(B 不是"每块都换 8 次"): 程序 B 命中率为 0,根本原因是数组一行的体积超过 Cache 总数据容量。如果数组改成 (一行 128B,Cache 还能装下 4 行),列优先访问就不再是 0% 命中了。
编者注(生僻术语): "局部性原理"包含时间局部性(刚访问过的还会再访问)和空间局部性(访问 X 之后多半会访问 X 附近)。本题考的是空间局部性:行优先访问行优先存放的数组,每读一块就用足 16 个元素,是教科书级别的空间局部性利用。