Appearance
题目
某计算机采用页式虚拟存储管理方式,按字节编址,虚拟地址为 32 位,物理地址为 24 位,页大小为 8KB;TLB 采用全相联映射;Cache 数据区大小为 64KB,按 2 路组相联方式组织,主存块大小为 64B。存储访问过程的示意图如下。
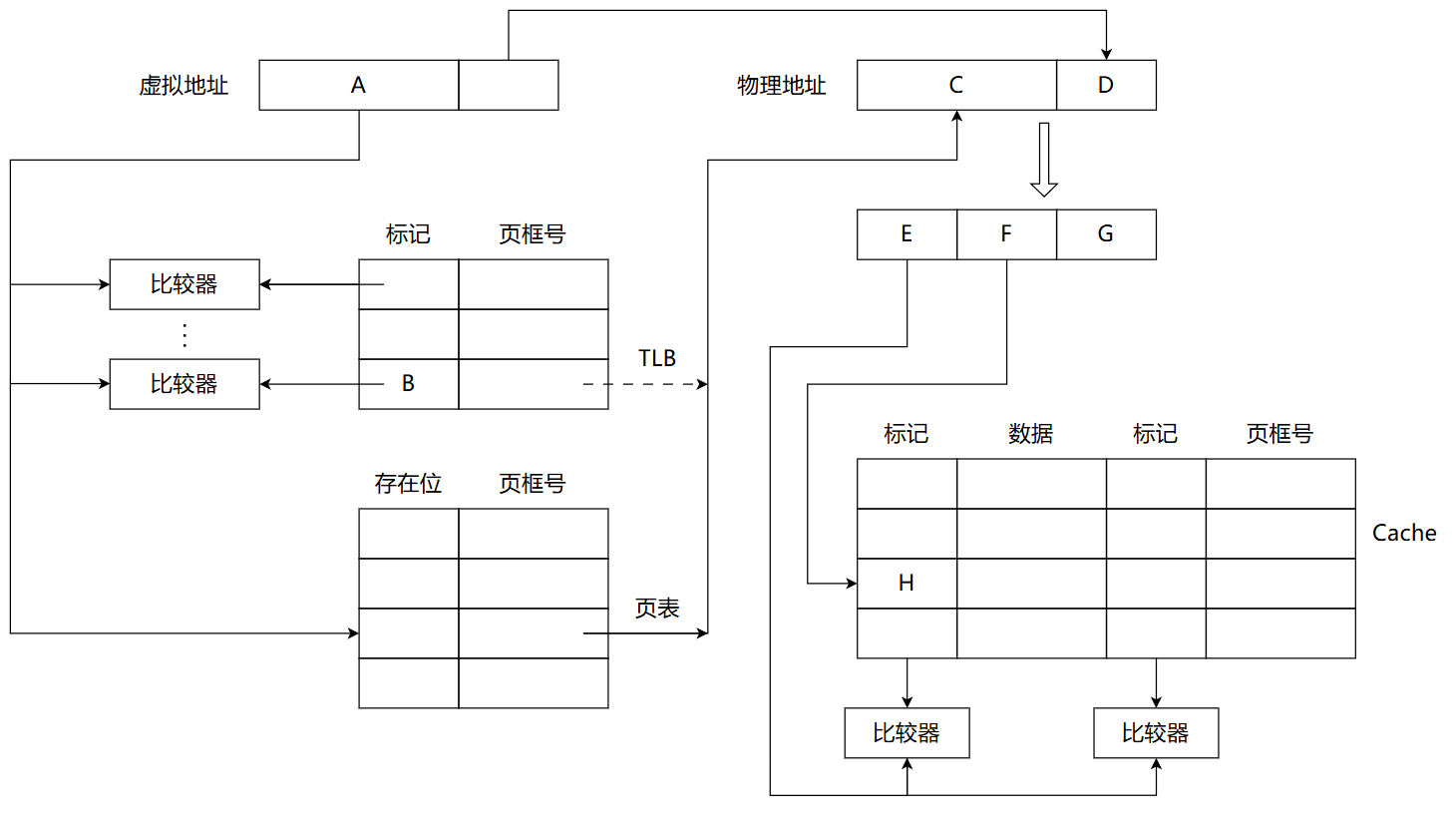
请回答下列问题。
(1) 图中字段 A~G 的位数各是多少?TLB 标记字段 B 中存放的是什么信息?
(2) 将块号为 4099 的主存块装入到 Cache 中时,所映射的 Cache 组号是多少?对应的 H 字段内容是什么?
(3) Cache 缺失处理的时间开销大还是缺页处理的时间开销大?为什么?
(4) 为什么 Cache 可以采用直写 (Write Through) 策略,而修改页面内容时总是采用回写 (Write Back) 策略?
解析
本题考查 页式虚拟存储 + 全相联 TLB + 2 路组相联 Cache 的字段拆分与跨层级一致性策略。地址沿"虚拟地址 → TLB → 物理地址 → Cache"流动,每一层都按各自的位段切分。
(1) 字段 A~G 的位数 + TLB 标记字段含义 [8 分]
先列基础参数:
- 虚拟地址 32 位、物理地址 24 位;
- 页大小 8KB → 页内偏移 = 位;
- 主存块大小 64B → 块内偏移 = 位;
- Cache 数据区 64KB,2 路组相联,每组 = → 组数 = → 组号 9 位。
字段位数:
| 字段 | 含义 | 位数 | 推导 |
|---|---|---|---|
| A | 虚页号 | 19 | |
| B | TLB 标记 | 19 | TLB 全相联 → 标记 = 虚页号 |
| C | 实页号 | 11 | |
| D | 页内偏移 | 13 | 页大小 8KB |
| E | Cache Tag | 9 | |
| F | Cache 组号 | 9 | 512 组 |
| G | 块内偏移 | 6 | 块 64B |
TLB 标记字段 B 存放的内容:虚页号。 全相联 TLB 没有"组号"概念,每项都要存完整的虚页号作为匹配键,命中后输出对应的实页号 C。
易错点: TLB 标记 = 完整虚页号(19 位),不是"虚页号去掉若干低位"。这是全相联结构与组相联 / 直接映射的关键差异。
(2) 块号 4099 映射到的 Cache 组号与 H 字段 [2 分]
Cache 字段在主存块号上的拆分: Tag(高 9 位)+ 组号(低 9 位)。即对 Cache 来说,"块号"已经把块内偏移 6 位剥离了,剩 18 位(24 − 6)用作 Tag + 组号。
按 [Tag 9 位 | 组号 9 位] 切(也就是高 9 位 + 低 9 位):
| 字段 | 二进制 | 十进制 |
|---|---|---|
| Tag(H 字段) | 000000010 | 8 |
| 组号 | 000000011 | 3 |
结论: 映射到 Cache 组 3,对应的 H 字段(即 Cache Tag)= 000001000B = 008H。
(3) Cache 缺失 vs 缺页:哪个开销更大?[2 分]
缺页开销远大于 Cache 缺失。
原因: Cache 缺失只需访问主存(DRAM,几十到上百 ns);缺页要访问磁盘(机械盘 ms 级,固态盘 μs 级,仍比主存慢若干数量级)。此外,缺页还要走 OS 的中断处理流程(软件介入),而 Cache 缺失由硬件直接处理。
【评分说明】若回答"因为缺页需要软件实现而 Cache 缺失用硬件实现",同样给分。
(4) 为什么 Cache 可用直写、缺页页面修改用回写 [2 分]
关键判断: 选择直写还是回写,看"上下两层介质的速度差"。
| 层级 | 上层(快) | 下层(慢) | 速度比 | 策略 |
|---|---|---|---|---|
| Cache ↔ 主存 | Cache(ns) | DRAM(10×ns) | ~10× | 直写可行 |
| 主存 ↔ 磁盘 | DRAM(10×ns) | 磁盘(μs~ms) | 必须回写 |
- 直写需要每次写都落到下层,下层若慢得离谱(如磁盘),CPU 就被拖死;
- 回写把多次写"积累"在上层,到时一次性写下,能把慢介质的访问次数降到最低。
写磁盘比写主存慢 4~6 个数量级,故主存 ↔ 磁盘只能用回写。
编者注(生僻术语): 真实 CPU 的 L1 Cache 多用回写(性能至上),共享 L2/L3 也偏向回写;早期 / 嵌入式 SoC 才用直写(实现简单、与设备一致性更好)。本题取的是教科书简化模型。