Appearance
海量数据排序 — 外部排序实战
场景引入
面试官问你:
"有一个 10GB 的订单文件,每行是一条 JSON 格式的订单记录,现在需要按照金额大小对所有订单进行排序,你会怎么做?"
这道题的核心挑战在于:一台机器的内存放不下全部数据。假设你的机器只有 2GB 可用内存,直接把 10GB 数据加载到内存排序,程序立刻 OOM。
这类问题的通用思路是分治——利用外存(磁盘),将数据分批加载到内存中处理。具体方案有两种:
- 外部归并排序:将大文件分割成多个小文件,分别排序后再多路归并
- 桶排序:按金额范围分桶,每个桶的文件足够小,可以在内存中排序
如果是单机处理,可以配合多线程加速;如果数据量更大(TB 级别),则需要用 MapReduce / Spark 等分布式方案。
本文不仅讲原理,更重要的是——我真的跑了这个实验,用 10GB 数据实测了两种方案的表现,用 JVM 监控工具记录了 CPU、内存、GC 的全过程。
核心思路
不管是归并排序还是桶排序,底层都是分治思想:
大文件(内存放不下)
↓ 分
多个小文件(每个内存能放下)
↓ 治
每个小文件在内存中排序
↓ 合
合并所有有序小文件 → 最终有序大文件从部署维度看:
| 维度 | 方案 | 关键点 |
|---|---|---|
| 单机单线程 | 分批加载,顺序处理 | 简单可靠,速度慢 |
| 单机多线程 | 线程池并行排序各分片 | CPU 利用率高,但要注意内存和 GC |
| 多机分布式 | MapReduce / Spark | Map 阶段分片排序,Reduce 阶段归并 |
方案一:外部归并排序
算法流程
外部归并排序分三步:
第一步:分割。 将 10GB 文件按大小切分成若干小文件,比如每个 1GB,得到 10 个子文件。
第二步:内排序。 将每个子文件加载到内存,用归并排序(或其他 O(n log n) 算法)排序后,写回磁盘。此时每个子文件内部有序。
第三步:多路归并。 为每个有序子文件分配一个读缓冲区(比如 100MB),同时维护一个输出缓冲区。每次从各缓冲区中取最小的元素,写入输出。某个缓冲区读完后,从对应的子文件中再读一批数据。
多路归并的核心是用一个最小堆(优先队列)来高效获取所有缓冲区中的最小值,时间复杂度为 O(N log K),其中 N 是总元素数,K 是子文件数。
实验过程
光讲理论没意思,我真的生成了一个 10GB 的订单数据文件来跑这个实验。
准备数据
生成 10GB 的订单 JSON 数据文件,每行格式如下:
json
{"orderId":"ORD-000001","amount":356.78,"userId":"U-98234","timestamp":1672531200}生成这个文件本身就花了 616 秒(约 10 分钟),这让我对后续的排序耗时有了心理准备。
单线程归并排序
首先尝试最朴素的方案:单线程读取 → 排序 → 写出。
JVM 参数:-Xms1536m -Xmx1536m
观察到的现象:
- CPU 利用率只有约 15%,大部分时间在等 IO
- 堆内存稳定在 ~1GB
- 排序一个 1GB 的子文件需要 1 小时以上
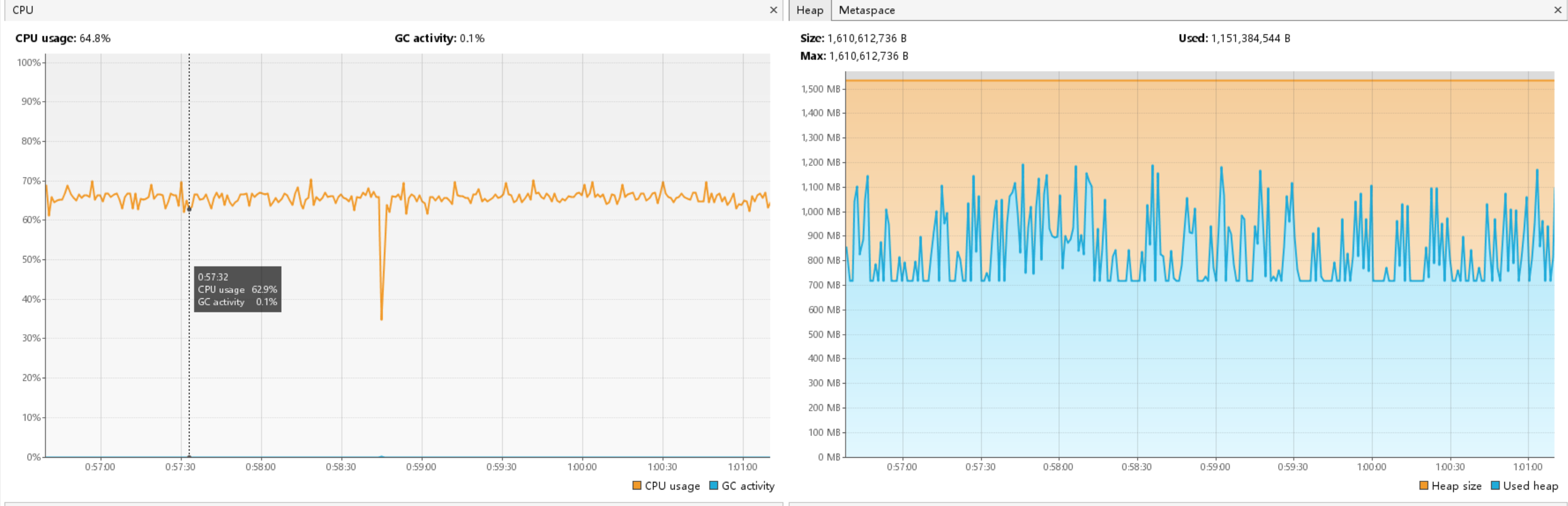
这速度完全不能接受。CPU 利用率这么低,说明排序过程是严重的计算密集型任务在单核上跑,其他核心完全闲置。
多线程归并排序
于是引入多线程。使用 ForkJoinPool 为每个子文件分配一个 worker 线程,并行排序。
java
ForkJoinPool forkJoinPool = new ForkJoinPool(THREAD_COUNT);
List<Future<?>> futures = new ArrayList<>();
for (int i = 0; i < subFileCount; i++) {
final int fileIndex = i;
futures.add(forkJoinPool.submit(() -> {
sortSubFile(fileIndex);
}));
}
// 等待所有子文件排序完成
for (Future<?> future : futures) {
future.get();
}
// 最终多路归并
multiWayMerge(subFileCount);效果立竿见影,CPU 利用率从 15% 飙升到 65%。
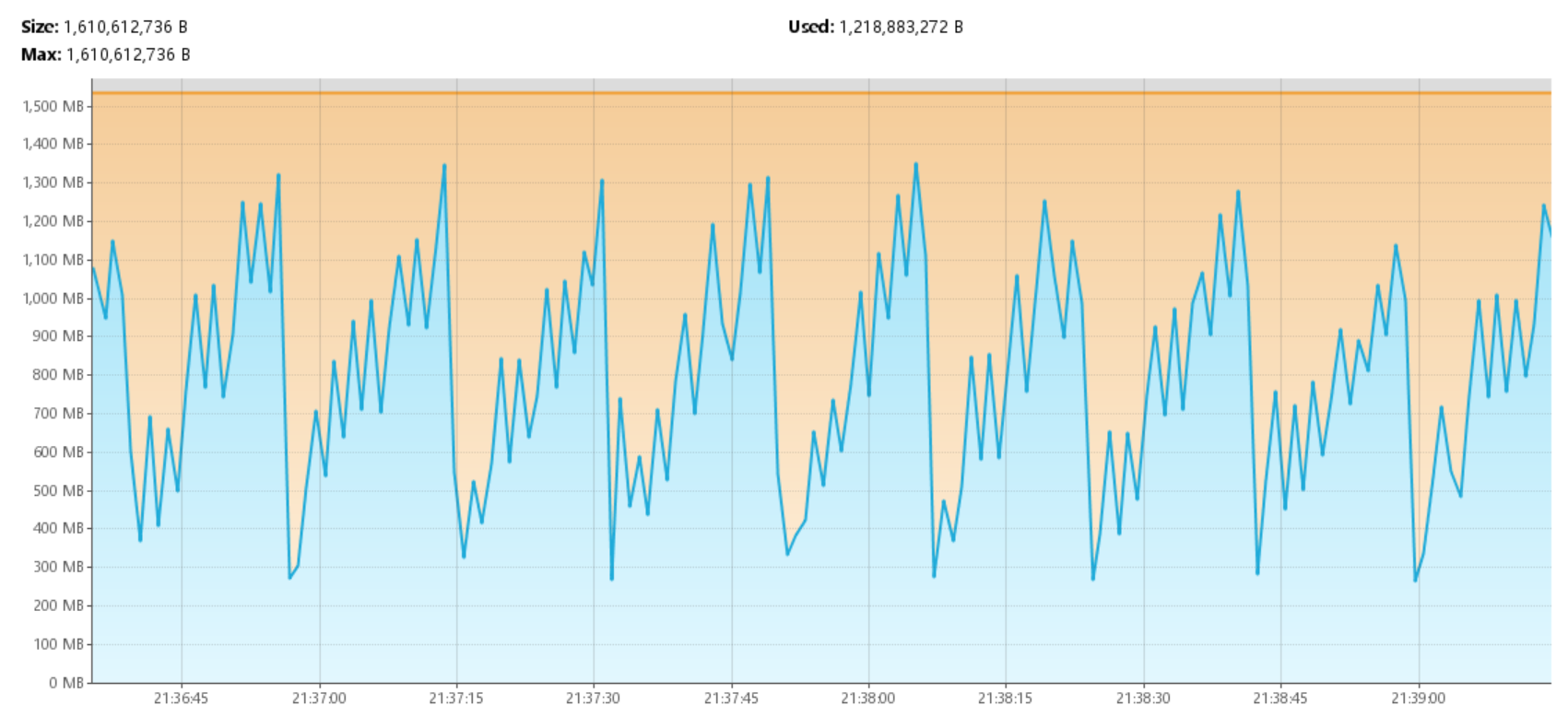
但是,监控中观察到一个有意思的现象:
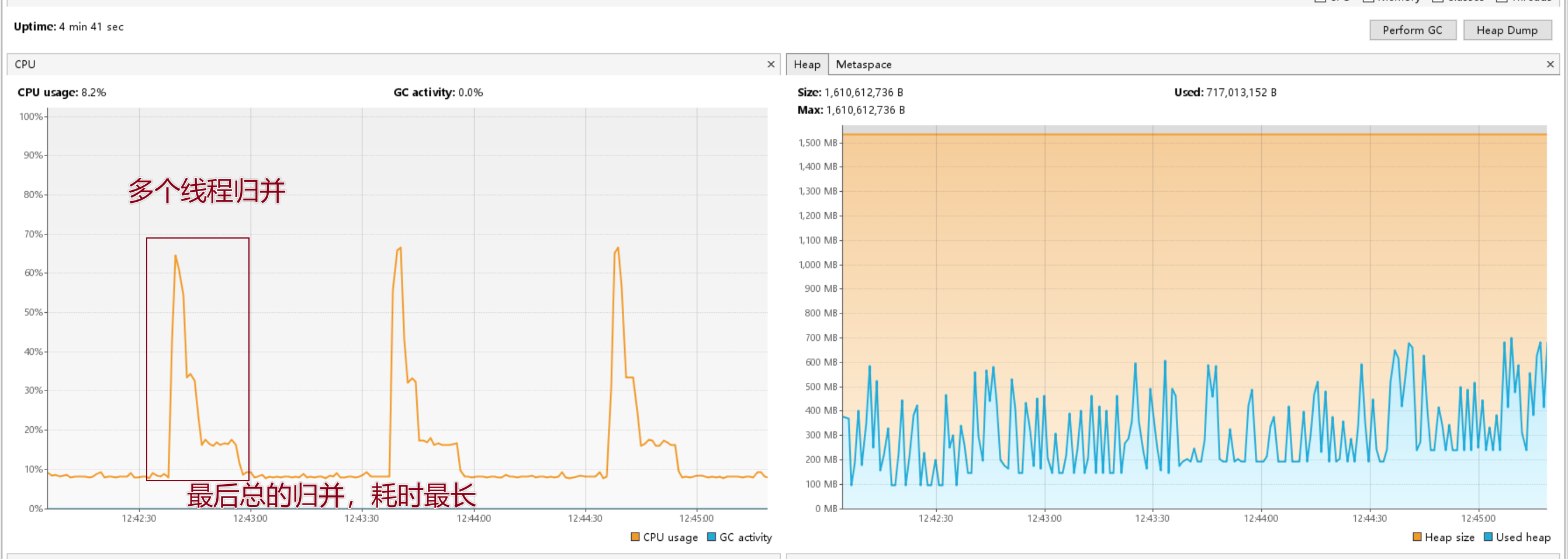
CPU 利用率先高后低。原因很简单:各个子文件的排序耗时不完全相同,先完成的线程就闲置了。到最后只剩一个线程在做最终的多路归并——这一步是整个流程中耗时最长的阶段,但它是单线程的。
这就是典型的阿姆达尔定律:并行部分再快,整体速度也受限于串行部分。
关键发现
在实验中,我还做了几组对比测试:
ArrayList vs 原生数组: 将排序容器从 ArrayList<String> 换成 String[],性能几乎没有提升。瓶颈不在数据结构的随机访问性能上。
调整 batchSize: 将每次读取的批量大小从 100000 调到 30000,单批次处理效率确实提高了(因为每批数据更少,排序更快),但总体时间反而更长。原因是批次变多之后,多线程并发的优势没有充分发挥——小任务的调度开销占比增大。
真正的瓶颈: 不是 IO,而是 CPU。对每一行 JSON 进行解析、提取金额字段、然后比较大小——这才是最耗时的操作。
代码示例
以下是分桶任务的核心代码,展示了单线程和多线程两种模式的处理逻辑:
java
for (int i = 0; i < PRICE_RANGE / STEP_LENGTH; i++) {
int start = i * STEP_LENGTH;
int end = start + STEP_LENGTH - 1;
if (USE_MULTI_THREAD){
tasks.add(new SortTask(start, end, i));
} else {
LargeFileReader largeFileReader = new LargeFileReader(SOURCE_FILE_PATH, READ_BATCH_SIZE);
List<String> outputLines = new LinkedList<>();
while (largeFileReader.canRead()){
List<String> nextLines = largeFileReader.getNextLines();
for (String nextLine : nextLines) {
if (OrderUtil.inRange(nextLine, start, end)){
outputLines.add(nextLine);
}
}
}
String sortedFileTemp = TEMP_FOLDER + "/" + i + ".txt";
FileUtil.appendToFile(outputLines, sortedFileTemp);
}
}其中 SortTask 封装了一个排序任务,包含金额范围和文件索引,提交给线程池执行。LargeFileReader 是自定义的大文件分批读取工具,避免一次性将整个文件加载到内存。
方案二:桶排序
算法流程
如果订单金额有一个已知的范围(比如 0 ~ 10000 元),可以用桶排序的思路:
- 按金额范围分桶,比如每 100 元一个桶:0-99、100-199、200-299 ...
- 遍历原始文件,将每条订单写入对应的桶文件
- 每个桶文件足够小,加载到内存中排序
- 按桶的顺序拼接所有桶文件,即为最终有序结果
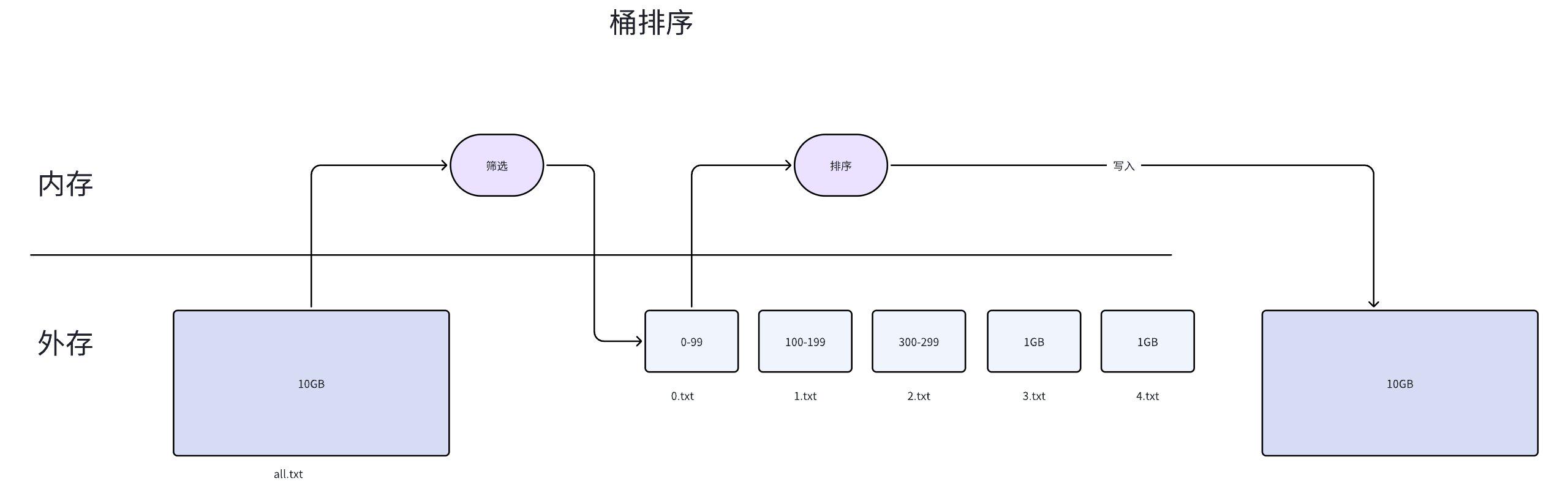
桶排序的优势在于:桶之间天然有序。0-99 的桶一定排在 100-199 前面,所以最后只需要按顺序拼接,不需要做多路归并。
实验过程
单线程桶排序
分桶阶段表现还不错——遍历一遍文件,按金额范围写入不同的桶文件,速度可以接受。
但问题出在排序阶段:即使数据被分到了不同的桶中,某些热门价格区间的桶文件仍然可能很大(数据分布不均匀)。一个 1GB 的桶文件在内存中排序,同样需要 1 小时以上。
多线程桶排序
自然的想法是多线程——多个线程同时读取、排序、写入不同的桶。
java
ExecutorService executor = Executors.newFixedThreadPool(THREAD_COUNT);
for (int i = 0; i < bucketCount; i++) {
final int bucketIndex = i;
executor.submit(() -> {
sortBucket(bucketIndex);
});
}然而,JVM 监控画面让人触目惊心:
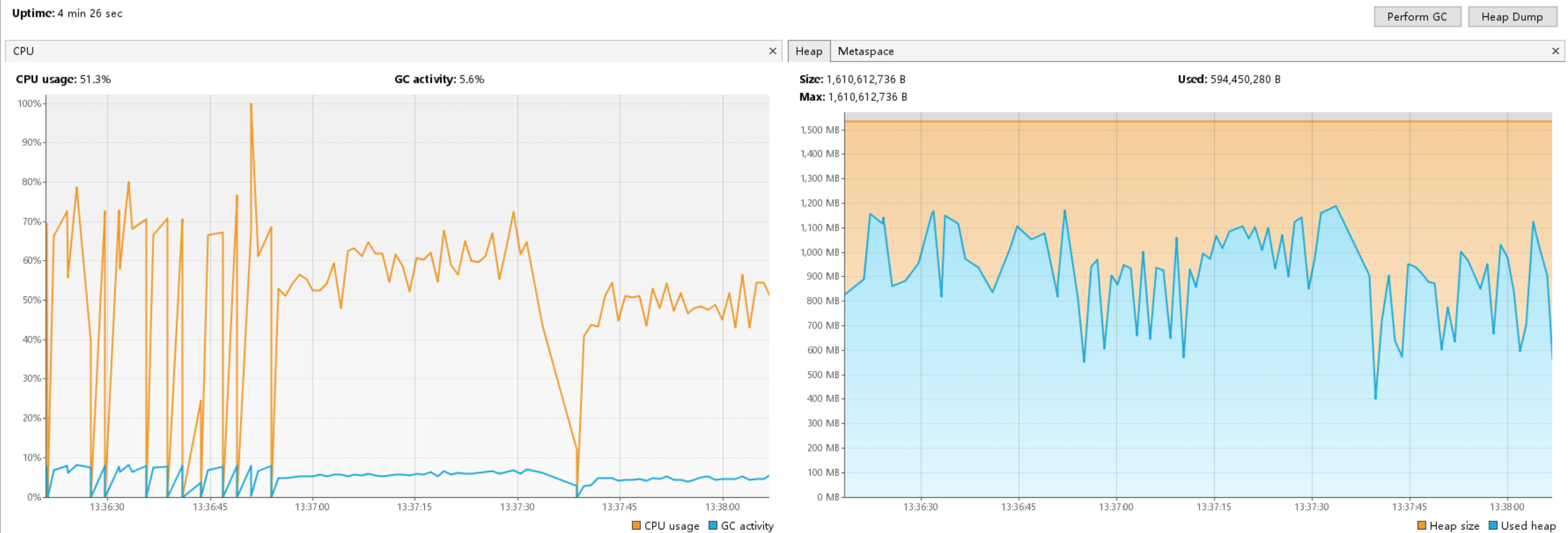
多个线程同时读取数据,导致大量数据同时加载到堆内存中。每个线程都需要维护自己的数据缓冲区,线程越多,内存消耗越大。堆空间迅速耗尽,触发频繁的 Full GC。
最终结果:java.lang.OutOfMemoryError: GC overhead limit exceeded
JVM 检测到程序花了超过 98% 的时间在做垃圾回收,但每次回收释放的内存不到 2%,直接抛出异常。
关键教训
多线程读取数据导致大量数据同时加载到内存,引发内存不足。拆分过程更适合单线程处理。
这是一个重要的认知:多线程不是万能的。在 IO 密集 + 内存受限的场景下,多线程反而会导致:
- 多个线程争抢有限的堆内存
- GC 压力倍增,STW(Stop-The-World)时间变长
- 吞吐量不升反降
更合理的策略是:分桶阶段用单线程(IO 密集,内存可控),排序阶段用多线程(CPU 密集,每个线程处理一个小桶)。
实验总结
经过对两种方案的完整实验,得出以下结论:
性能瓶颈分析
| 阶段 | 瓶颈 | 原因 |
|---|---|---|
| 数据生成 | IO | 大量磁盘写入 |
| 分割/分桶 | IO | 顺序读 + 随机写 |
| 内存排序 | CPU | JSON 解析 + 比较操作 |
| 多路归并 | CPU + IO | 多文件同时读写 |
个人电脑上,CPU 是海量数据排序的主要瓶颈。 这与很多人的直觉相反——大家通常以为瓶颈在 IO,但实际上磁盘顺序读写的速度远快于"解析 JSON 并提取字段进行比较"的速度。
多线程的两面性
- 并行排序多个子文件时,CPU 利用率从 15% 提升到 65%,效果显著
- 但随着线程逐步完成任务,CPU 利用率逐步下降,最终只剩一个线程在做归并
- 桶排序中多线程同时加载数据,反而导致 Full GC 和 OOM
- 多线程适合 CPU 密集的并行计算,不适合内存密集的并行加载
JVM 调优建议
在实验中使用的 JVM 配置:
-Xms1536m -Xmx1536m监控工具:
jstat -gc <pid> 1000:实时查看 GC 频率和耗时- VisualVM:可视化监控 CPU、堆内存、线程状态
经验:将 -Xms 和 -Xmx 设为相同值,避免堆的动态扩缩容引起额外的 GC 开销。
生产环境建议
个人电脑跑 10GB 排序是一个学习实验。在生产环境中,海量数据排序的标准做法是:
- Hadoop MapReduce:Map 阶段将数据按 key 分片排序,Shuffle 阶段按 key 分发,Reduce 阶段归并
- Apache Spark:用
sortByKey或repartitionAndSortWithinPartitions,利用内存计算加速 - 数据库外部排序:MySQL、PostgreSQL 等数据库的
ORDER BY在数据量大时,底层就是外部归并排序
面试要点
回答"海量数据排序"这类面试题,建议按以下结构组织:
第一步:明确约束
- 数据量多大?一台机器能放下吗?
- 内存限制是多少?
- 需要排序的字段是什么?数据格式是什么?
第二步:给出方案
首选:外部归并排序
将大文件分成多个小文件,每个小文件加载到内存中用归并排序排好序,最后用多路归并将所有有序小文件合并成最终结果。多路归并用最小堆来高效取最小值。
备选:桶排序
如果排序字段的值域已知且有限(比如金额在 0~10000),可以按值域分桶。分桶后每个桶文件较小,可以直接在内存中排序。桶之间天然有序,最后顺序拼接即可。
第三步:扩展加分
- 单机可以用多线程并行排序各个子文件,提升 CPU 利用率
- 数据量到 TB 级别,用 MapReduce 或 Spark 分布式处理
- 注意 JVM 内存管理,避免多线程同时加载大量数据导致 Full GC
- 多路归并时使用优先队列(最小堆),时间复杂度 O(N log K)
答题模板
分治 → 分片(分割/分桶)→ 排序(内存排序)→ 归并(多路归并/顺序拼接)记住这四个关键词,面试时不会遗漏要点。