Appearance
海量数据求TopK与频率统计
场景引入
面试中有两道经典的海量数据题:
题目一:10亿个整数存在文件中,内存有限(比如只有 512MB),如何找出最大的 Top 100 个整数?
题目二:100GB 的搜索关键字日志文件,如何统计出现频率最高的 Top 100 个关键词?
这两道题看似相似,但解法不同。第一题的关键是极值筛选,第二题的关键是频率聚合。
它们有一个共同点:数据量远超内存,不可能一次加载到内存中处理。
下面分别拆解。
题型三:海量数据求TopK
核心思路
这道题的标准答案是小顶堆(Min-Heap)。
思路非常直觉:维护一个大小为 K 的小顶堆,从文件中分批读取数据,每读到一个数就往堆里塞。堆满了(size > K)就弹出堆顶——堆顶是当前堆中最小的元素,弹掉它正好保留了更大的数。
遍历完所有数据后,堆中剩下的就是最大的 K 个元素。
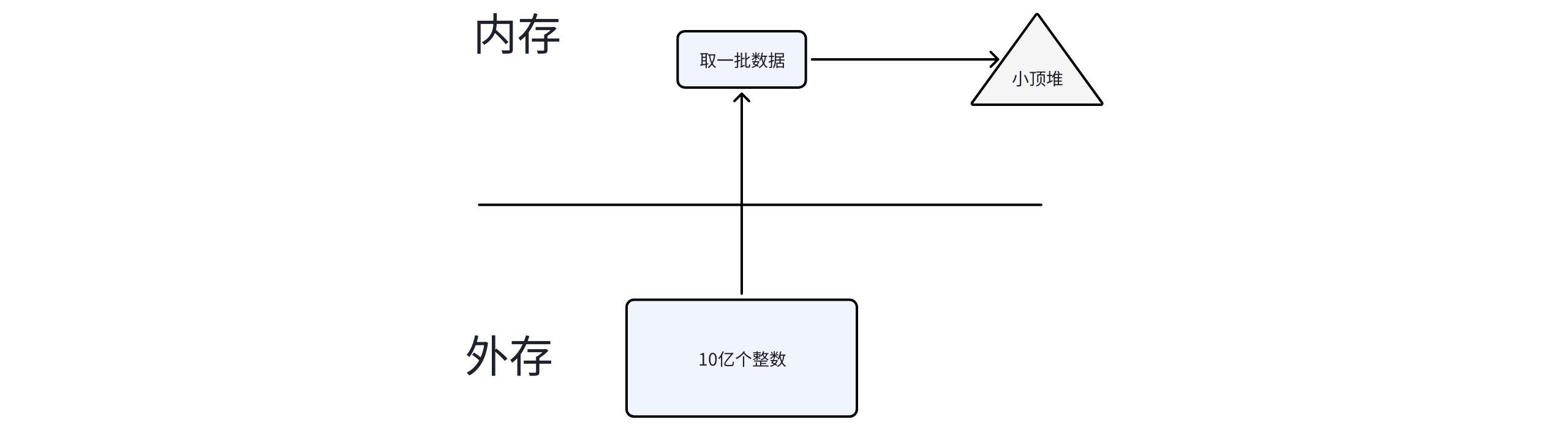
为什么用小顶堆而不是大顶堆?
- 大顶堆:堆顶是最大值,弹出的是最大值,留下的反而是小的——方向反了。
- 小顶堆:堆顶是最小值,弹出最小值,留下的都是大的——正好是我们要的。
复杂度分析:
- 时间:O(N log K),N 是总数据量,每个元素最多做一次堆插入 O(log K)
- 空间:O(K),堆的大小固定为 K
三个层次的解法
面试中如果面试官追问"还能怎么优化",可以逐步升级:
| 层级 | 方案 | 适用场景 |
|---|---|---|
| 单机单线程 | 小顶堆 | 数据量大但单机能处理 |
| 单机多线程 | 小顶堆 + 多线程分片 | 尝试用多核加速 |
| 多机分布式 | 小顶堆 + MapReduce | 数据量极大,单机处理太慢 |
下面用代码实验每个层级的实际表现。
单线程实现
最基础的版本,用 Java 内置的 PriorityQueue(默认就是小顶堆):
java
static PriorityQueue<Integer> findTopK(){
LargeFileReader largeFileReader = new LargeFileReader(SOURCE_FILE_PATH, BATCH_SIZE);
PriorityQueue<Integer> queue = new PriorityQueue<>();
while (largeFileReader.canRead()){
List<String> nextLines = largeFileReader.getNextLines();
for (String nextLine : nextLines) {
queue.add(Integer.parseInt(nextLine));
if (queue.size() > K_VALUE){
queue.poll();
}
}
}
return queue;
}代码逻辑:
LargeFileReader封装了分批读取大文件的逻辑,每次读BATCH_SIZE行- 对每一行解析成整数,加入小顶堆
- 堆的大小超过 K 就弹出堆顶(最小值)
- 遍历结束,堆中就是最大的 K 个数
实验结果:10亿整数文件,K=100,耗时约 180s。
180秒——能不能用多线程加速?
多线程实现
思路:把文件分给多个线程读,每个线程各自维护一个小顶堆求局部 TopK,最后把所有线程的结果合并。
java
public static PriorityQueue<Integer> findTopKV2() throws InterruptedException, IOException, ExecutionException {
LargeFileReader largeFileReader = new LargeFileReader(SOURCE_FILE_PATH, BATCH_SIZE);
ExecutorService executorService = Executors.newFixedThreadPool(CORE_SIZE);
List<Future<PriorityQueue<Integer>>> futures = new ArrayList<>();
for (int i = 0; i < CORE_SIZE; i++) {
TopKFinder finder = new TopKFinder(K_VALUE, largeFileReader);
Future<PriorityQueue<Integer>> future = executorService.submit(finder);
futures.add(future);
}
List<PriorityQueue<Integer>> queues = new ArrayList<>();
for (Future<PriorityQueue<Integer>> future : futures) {
queues.add(future.get());
}
executorService.shutdown();
return MergeTopK.merge(queues, K_VALUE);
}每个线程执行的 TopKFinder:
java
class TopKFinder implements Callable<PriorityQueue<Integer>> {
private final int kValue;
private final LargeFileReader reader;
public TopKFinder(int kValue, LargeFileReader largeFileReader) {
this.reader = largeFileReader;
this.kValue = kValue;
}
@Override
public PriorityQueue<Integer> call() {
PriorityQueue<Integer> queue = new PriorityQueue<>();
while (reader.canRead()) {
List<String> nextLines = reader.getNextLines();
for (String line : nextLines) {
int value = Integer.parseInt(line);
queue.add(value);
if (queue.size() > kValue) {
queue.poll();
}
}
}
return queue;
}
}多个线程的局部结果需要合并,MergeTopK 把所有局部堆合成一个全局 TopK:
java
class MergeTopK {
public static PriorityQueue<Integer> merge(List<PriorityQueue<Integer>> queues, int kValue) {
PriorityQueue<Integer> finalQueue = new PriorityQueue<>();
for (PriorityQueue<Integer> queue : queues) {
while (!queue.isEmpty()) {
finalQueue.add(queue.poll());
if (finalQueue.size() > kValue) {
finalQueue.poll();
}
}
}
return finalQueue;
}
}实验对比
多线程真的能加速吗?实验结果出乎意料:
| 方案 | 耗时 | 说明 |
|---|---|---|
| 单线程小顶堆 | 180s | 基准方案 |
| 多线程(预处理分片) | >180s | 光是把数据分片写到多个文件就超过 180s |
| 多线程(加锁共享读) | 257s | 为线程安全对文件读取加锁,CPU 利用率反而很低 |
| 多线程(无锁方案) | ~120s | 有提升但不明显 |
为什么多线程没用?
瓶颈在 IO,不在 CPU。
TopK 问题的计算量极小——每个元素只做一次堆插入,O(log K) 在 K=100 时几乎可以忽略。真正耗时的是从磁盘读取 10 亿行数据。
多线程的问题:
- 文件读取是天然的串行操作。多个线程共享一个文件读取器,要么加锁(降低并发度),要么无锁(需要复杂的线程安全设计)
- 加锁后反而更慢。线程大部分时间在等锁,CPU 利用率只有个位数百分比
- 预处理分片本身就很慢。把一个大文件拆成多个小文件,IO 开销已经超过了单线程直接处理的时间
结论:对于 IO 密集型的 TopK 问题,多线程并没有太大提升。单线程小顶堆就是最实用的方案。
如果真的要加速,方向应该是:
- SSD 替换 HDD:提升磁盘读取速度
- 多机分布式:数据本身就分布在多台机器上,各自求局部 TopK 再合并
- 内存映射文件(mmap):减少系统调用开销
题型四:海量数据频率统计
核心思路
频率统计和 TopK 不同——你不仅要知道谁大,还要先数清楚每个元素出现了多少次。
两种思路:
思路一:排序再统计
先对 100GB 的数据做外部排序,排好序后相同的元素一定相邻,再扫描一遍统计频率。
问题:这又回到了海量数据排序问题,排序本身就很慢。
思路二:Hash 分片 → 分片统计 → 汇总 TopK
这是更好的方案:
- 分片:对每个关键字取 hash,按 hash 值分到不同的小文件中。相同的关键字一定会被分到同一个文件
- 分片统计:对每个小文件,用 HashMap 统计词频,再用小顶堆求该文件的 Top K
- 全局汇总:把所有分片的 Top K 结果合并,再用小顶堆求全局 Top K
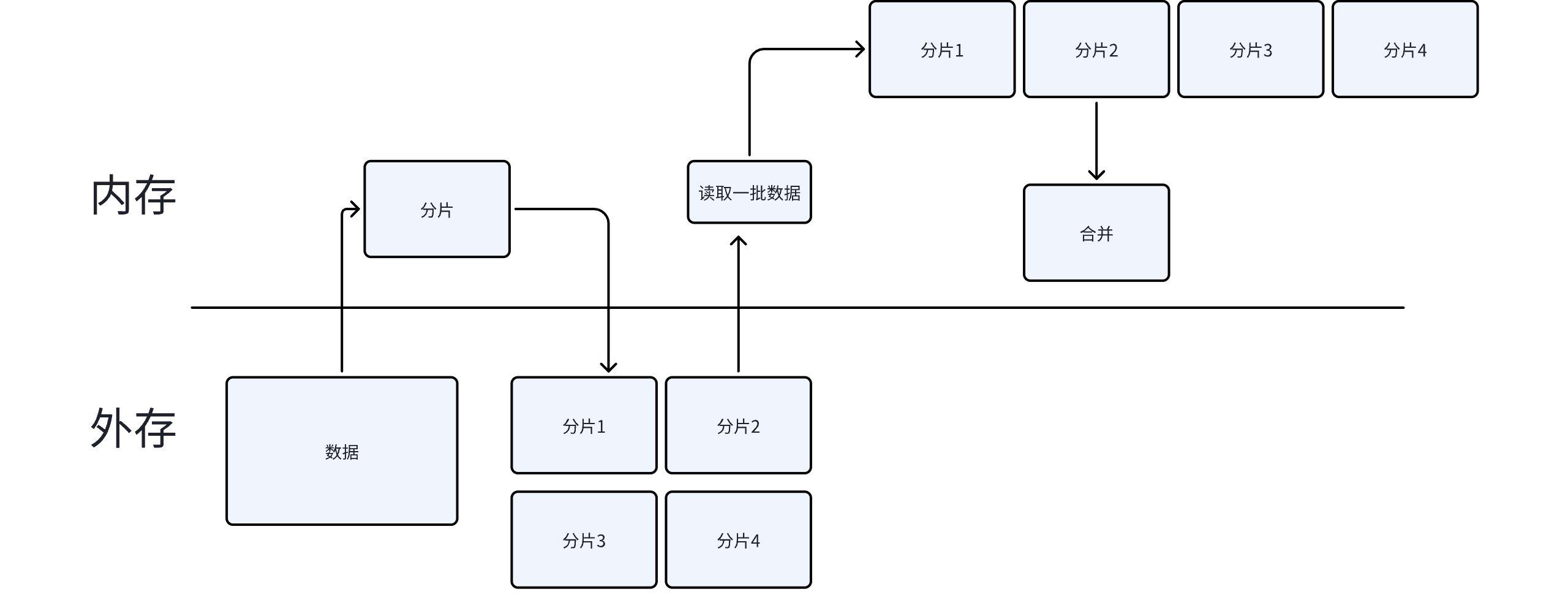
为什么 Hash 分片能工作?
关键在于:hash(keyword) % N 保证相同的关键字一定落在同一个分片中。这样每个分片可以独立统计词频,不会漏算。
分片实现
先把大文件按 hash 分成多个小文件:
java
public static void divide(){
for (int i = 0; i < TOTAL_INT_COUNT; i++) {
LargeFileReader reader = new LargeFileReader(SOURCE_FILE_PATH, BATCH_SIZE);
List<Integer> outPutList = new LinkedList<>();
while (reader.canRead()){
List<String> nextLines = reader.getNextLines();
for (String nextLine : nextLines) {
int intVal = Integer.parseInt(nextLine);
if (intVal % 10 == i){
outPutList.add(intVal);
}
}
}
FileUtil.appendToFile(outPutList, TEMP_FOLDER_PATH + "/" + i + ".txt");
}
}这里用 intVal % 10 做分片,把数据分成 10 个文件。实际生产中分片数可以根据内存大小调整——确保每个分片的数据能放进内存做 HashMap 统计。
分片统计 + 汇总 TopK
对每个分片文件,用 HashMap 统计词频,再用小顶堆求局部 TopK,最后合并所有分片的结果:
java
public static LinkedHashMap<Integer,Integer> topFreqK() {
divide();
File file = new File(TEMP_FOLDER_PATH);
File[] files = file.listFiles();
PriorityQueue<Map.Entry<Integer,Integer>> q = new PriorityQueue<>(Map.Entry.comparingByValue());
for (File f : files) {
Map<Integer, Integer> freq = new HashMap<>();
LargeFileReader largeFileReader = new LargeFileReader(f.getAbsolutePath(), BATCH_SIZE);
while (largeFileReader.canRead()){
List<String> nextLines = largeFileReader.getNextLines();
for (String nextLine : nextLines) {
int value = Integer.parseInt(nextLine);
freq.put(value,freq.getOrDefault(value,0)+1);
}
}
PriorityQueue<Map.Entry<Integer, Integer>> entries = fromMap(freq);
q.addAll(entries);
while (q.size() > K_VALUE) {
q.poll();
}
}
LinkedHashMap<Integer, Integer> res = new LinkedHashMap<>();
for (Map.Entry<Integer, Integer> et : q) {
res.put(et.getKey(), et.getValue());
}
return res;
}代码逻辑:
- 先调用
divide()完成分片 - 遍历每个分片文件,用
HashMap<Integer, Integer>统计词频 - 把当前分片的词频结果加入全局小顶堆(按频率排序)
- 堆大小超过 K 就弹出频率最低的
- 最终堆中就是全局频率 Top K
分片数怎么定?
分片数的选择原则:每个分片的数据量 < 可用内存。
举个例子:
- 100GB 数据,可用内存 4GB
- 分片数 = 100GB / 4GB = 25,取 32(2 的幂次更方便取模)
- 每个分片约 3.1GB,可以放进内存用 HashMap 统计
如果某个分片因为 hash 冲突导致数据倾斜,超出内存限制,可以对该分片再做二次分片。
面试要点总结
TopK 问题
| 维度 | 要点 |
|---|---|
| 核心数据结构 | 小顶堆(PriorityQueue) |
| 时间复杂度 | O(N log K) |
| 空间复杂度 | O(K) |
| 为什么不排序 | 排序是 O(N log N),且需要 O(N) 空间 |
| 多线程有用吗 | 帮助有限,瓶颈在 IO 不在 CPU |
| 分布式方案 | 各节点求局部 TopK,汇总节点合并 |
频率统计问题
| 维度 | 要点 |
|---|---|
| 核心思路 | Hash 分片 + HashMap 统计 + 小顶堆 |
| 分片目的 | 让相同元素落在同一分片,且单个分片能放进内存 |
| 时间复杂度 | 分片 O(N) + 统计 O(N) + TopK O(N log K) |
| 分布式方案 | MapReduce:Map 阶段按 key 分片统计,Reduce 阶段汇总 |
面试回答模板
TopK 问题:
维护一个大小为 K 的小顶堆,分批从文件读取数据,每个元素入堆后如果堆大小超过 K 就弹出堆顶。遍历完成后堆中就是最大的 K 个元素。时间 O(N log K),空间 O(K)。如果是分布式场景,每台机器各自求局部 TopK,最后合并。
频率统计问题:
先用 Hash 分片把数据拆成多个小文件,保证相同的关键字落在同一个文件。然后对每个小文件用 HashMap 统计词频,再用小顶堆求局部 Top K。最后把所有分片的结果合并求全局 Top K。分布式场景就是 MapReduce。
延伸问题
面试官可能会继续追问:
- 如果 K 很大怎么办? K 很大时堆操作的 log K 不可忽略,可以考虑快速选择算法 O(N)
- 如果数据是流式的怎么办? 用堆在线维护 TopK,每来一个新数据就更新堆
- 如果要求近似结果可以吗? 可以用 Count-Min Sketch 做近似频率统计,用 Lossy Counting 做近似 TopK
- MapReduce 具体怎么做? Map 阶段输出 (key, 1),Combiner 做局部聚合,Reduce 阶段求全局频率再取 TopK