Appearance
海量数据查询、去重与找重
场景引入
面试中,海量数据问题经常以不同的面貌出现,但本质上都是同一类问题。看看下面这几道经典题:
- 有一个 IP 地址白名单文件,包含 10 亿个 IP 地址,判断某 IP 是否在白名单中?
- 10 亿个整数,判断某个整数是否在其中?
- 一个文件中包含 10 亿条 URL,有可能会重复,将重复的去掉。
- 给你 a、b 两个文件,各自有 50 亿条 URL,每条 URL 占用 64 字节,内存限制是 4GB,找出 a、b 文件共同的 URL。
它们看起来各不相同,但剥开表象,核心都是同一个问题:海量数据的存在性判断与集合运算。
我们把这些问题归纳为三种题型:
| 题型 | 代表问题 |
|---|---|
| 查询(存在性判断) | IP 白名单、整数查找 |
| 去重 | 10 亿条 URL 去重 |
| 找重(求交集) | 两文件 50 亿 URL 求交集 |
下面逐一拆解。
题型一:海量数据查询
问题描述
- IP 白名单 10 亿个,判断某 IP 是否存在
- 10 亿个整数,判断某整数是否存在
这类问题的核心就是一个词:存在性判断。
方案递进
解决存在性查询,方案可以逐步递进,根据数据量和内存限制选择最合适的:
方案一:哈希表
如果内存放得下,最简单粗暴的方式就是直接用 HashMap 或 HashSet,查询时间 O(1)。
java
// 最直接的方案:HashSet
Set<Integer> set = new HashSet<>();
// 将 10 亿个整数加入 set
for (int num : data) {
set.add(num);
}
// O(1) 查询
boolean exists = set.contains(target);但问题来了——内存放得下吗?
方案二:位图(BitSet)
当哈希表内存放不下时,位图是绝佳的替代方案。
核心思想:用一个 bit 表示一个整数是否存在。第 i 位为 1 表示整数 i 存在,为 0 表示不存在。
java
// BitSet 方案
BitSet bitSet = new BitSet();
// 将 10 亿个整数对应的位设为 1
for (int num : data) {
bitSet.set(num);
}
// O(1) 查询
boolean exists = bitSet.get(target);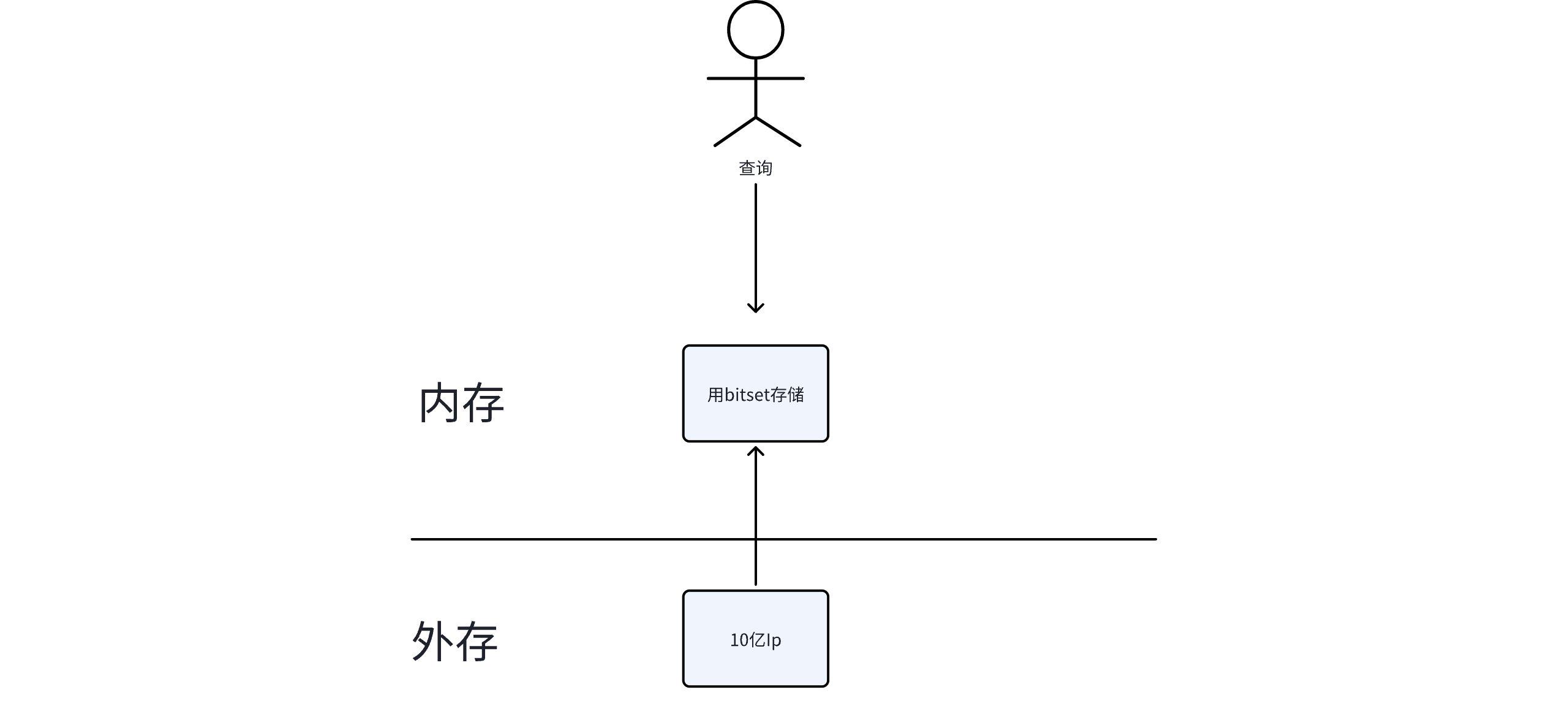
方案三:布隆过滤器
如果允许少量误判(如反垃圾邮件场景),布隆过滤器的空间效率更高。
布隆过滤器用多个哈希函数将元素映射到位数组的多个位置。查询时,所有位置都为 1 才判断「可能存在」;只要有一个位置为 0,就一定不存在。
java
// Guava 的布隆过滤器
BloomFilter<Integer> filter = BloomFilter.create(
Funnels.integerFunnel(),
1_000_000_000, // 预期插入量
0.01 // 误判率 1%
);
for (int num : data) {
filter.put(num);
}
// 查询:可能存在 or 一定不存在
boolean mightExist = filter.mightContain(target);特点:
- 说「不存在」就一定不存在
- 说「存在」有小概率误判
- 空间比 BitSet 更省
方案四:多机哈希表
一台机器放不下?那就分区到多台机器。按 hash(key) % N 将数据分散到 N 台机器上,查询时根据哈希值路由到对应机器。
关键计算
来算一笔帐,直观感受各方案的内存差距:
| 方案 | 10 亿个 int 所需内存 | 说明 |
|---|---|---|
| HashMap | 约 16GB | 每个 Entry 约 16 字节(key + value + hash + next 指针) |
| BitSet | 约 125MB | 10 亿 bit = 10^9 / 8 字节 ≈ 125MB |
| 布隆过滤器 | 约 1.2GB(1% 误判率) | 每个元素约 10 bit |
BitSet 相比 HashMap,空间节省 100 倍以上。
这就是为什么面试官喜欢追问「内存不够怎么办」——他想听到你从 HashMap 过渡到 BitSet 或布隆过滤器的思考过程。
IP 地址的处理技巧
IP 地址本质上就是一个 32 位整数。例如 192.168.1.1 可以转换为一个 int:
java
public static int ipToInt(String ip) {
String[] parts = ip.split("\\.");
int result = 0;
for (String part : parts) {
result = (result << 8) | Integer.parseInt(part);
}
return result;
}转成整数后,就能直接用 BitSet 来处理了。32 位整数的范围是 0 到 2^32 - 1(约 42 亿),用 BitSet 存储只需约 512MB。
题型二:海量数据去重
问题描述
一个文件中包含 10 亿条 URL,可能有重复,将重复的去掉。
URL 是字符串,不像整数可以直接用 BitSet。假设每条 URL 平均 64 字节,10 亿条就是 64GB 数据,内存根本放不下。
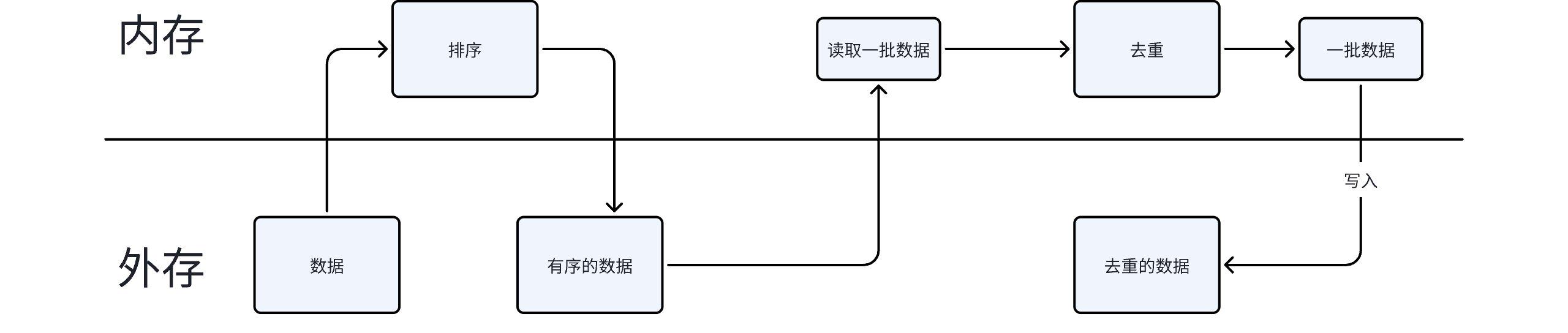
解法一:排序去重
思路很直接:
- 先对文件进行外部排序(参考上一篇的多路归并排序)
- 排序后,相同的 URL 一定相邻
- 线性扫描,跳过重复项即可
java
// 排序后去重(伪代码)
BufferedReader reader = new BufferedReader(new FileReader("sorted_urls.txt"));
BufferedWriter writer = new BufferedWriter(new FileWriter("unique_urls.txt"));
String prev = null;
String line;
while ((line = reader.readLine()) != null) {
if (!line.equals(prev)) {
writer.write(line);
writer.newLine();
prev = line;
}
}缺点:需要先完成外部排序,时间复杂度 O(N log N),IO 开销大。
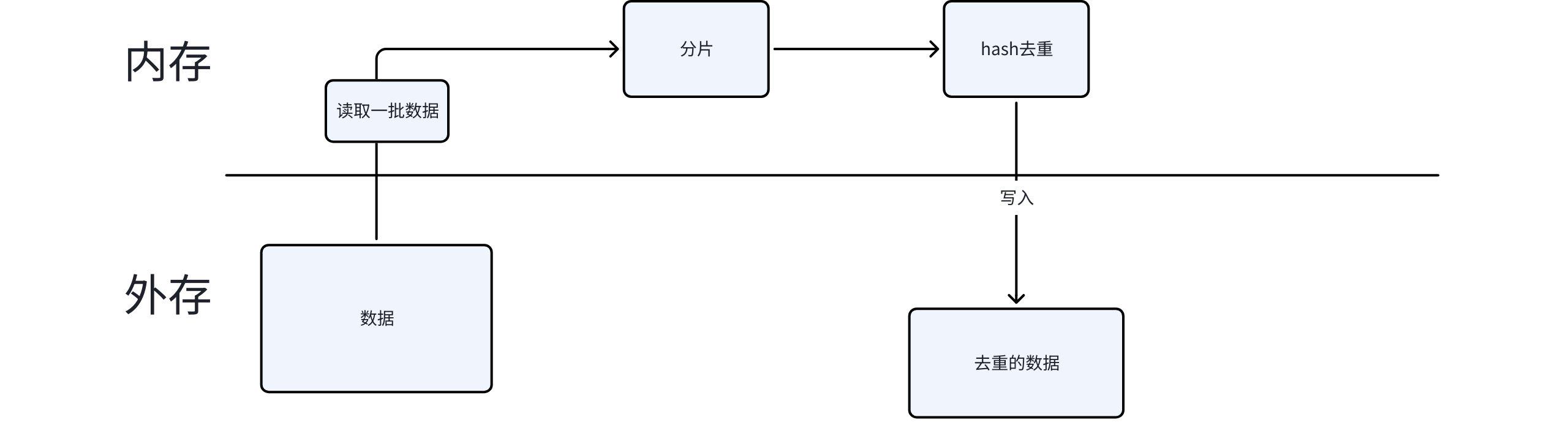
解法二:哈希分片
这是更优的方案,核心思想是分而治之:
- 读取数据,按 hash 值分片到多个小文件:
hash(url) % K决定分到第几个文件 - 对每个小文件,用 HashSet 去重
- 关键保证:相同的 URL 一定被分到同一个片中,所以去重的完整性有保证
java
// 第一步:哈希分片
int K = 1000; // 分成 1000 个小文件
BufferedWriter[] writers = new BufferedWriter[K];
for (int i = 0; i < K; i++) {
writers[i] = new BufferedWriter(new FileWriter("part_" + i + ".txt"));
}
BufferedReader reader = new BufferedReader(new FileReader("urls.txt"));
String line;
while ((line = reader.readLine()) != null) {
int partition = (line.hashCode() & 0x7FFFFFFF) % K;
writers[partition].write(line);
writers[partition].newLine();
}
// 第二步:逐片去重
for (int i = 0; i < K; i++) {
Set<String> set = new HashSet<>();
BufferedReader partReader = new BufferedReader(new FileReader("part_" + i + ".txt"));
while ((line = partReader.readLine()) != null) {
set.add(line);
}
// 将 set 中的内容写入结果文件
for (String url : set) {
resultWriter.write(url);
resultWriter.newLine();
}
set.clear(); // 释放内存
}为什么分 1000 片? 10 亿条 URL 共约 64GB,分 1000 片后每片约 64MB,内存轻松放下。
Hash 方式的处理过程和频率统计题型(用 HashMap 统计词频)非常类似,只是这里用 HashSet 而非 HashMap。
题型三:海量数据找重(两文件求交集)
问题描述
给你 a、b 两个文件,各自有 50 亿条 URL,每条 URL 占用 64 字节,内存限制是 4GB,找出 a、b 文件共同的 URL。
内存分析
先算一笔帐:
- 单个文件:50 亿 x 64 字节 = 320GB
- 两个文件合计:640GB
- 可用内存:4GB
内存远远不够,必须分片处理。
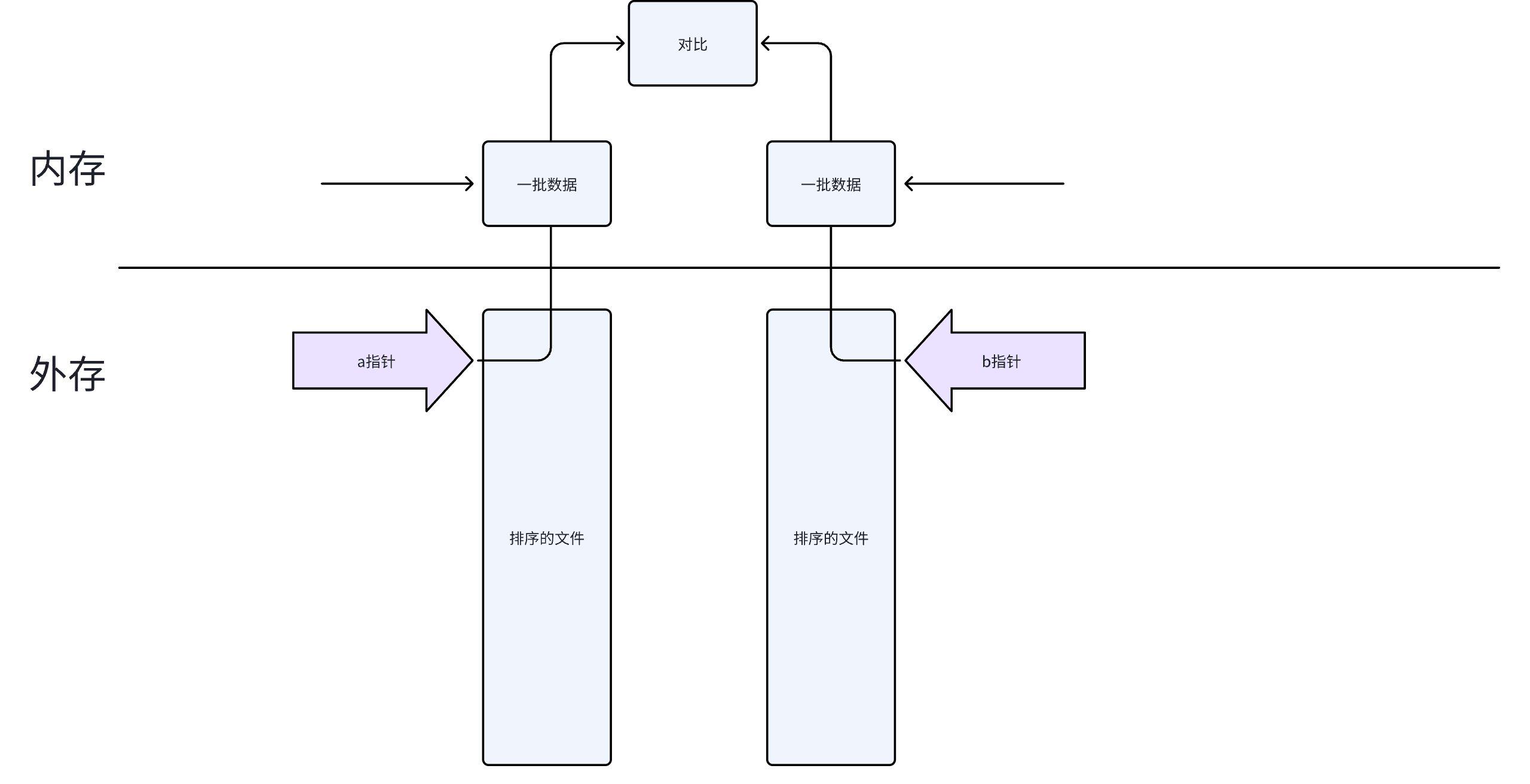
解法一:排序 + 双指针
- 分别对 a、b 文件进行外部排序
- 用双指针法,从两个排序文件头部开始同时扫描
- 两个指针指向的值相等 → 加入结果,两个指针都前进
- 不相等 → 移动指向较小值的那个指针
java
// 排序后,双指针求交集(伪代码)
BufferedReader readerA = new BufferedReader(new FileReader("sorted_a.txt"));
BufferedReader readerB = new BufferedReader(new FileReader("sorted_b.txt"));
BufferedWriter writer = new BufferedWriter(new FileWriter("intersection.txt"));
String lineA = readerA.readLine();
String lineB = readerB.readLine();
while (lineA != null && lineB != null) {
int cmp = lineA.compareTo(lineB);
if (cmp == 0) {
writer.write(lineA);
writer.newLine();
lineA = readerA.readLine();
lineB = readerB.readLine();
} else if (cmp < 0) {
lineA = readerA.readLine();
} else {
lineB = readerB.readLine();
}
}缺点:依赖外部排序,排序本身就是大工程。
解法二:哈希分片
这是面试中最推荐的方案:
- 对 a、b 文件都按相同的 hash 函数分片:
hash(url) % K - 相同的 URL 一定被分到对应编号的分片中(a 的第 i 片和 b 的第 i 片)
- 对每对对应的分片(a1 与 b1、a2 与 b2 ...),在内存中用 HashSet 查找共同 URL
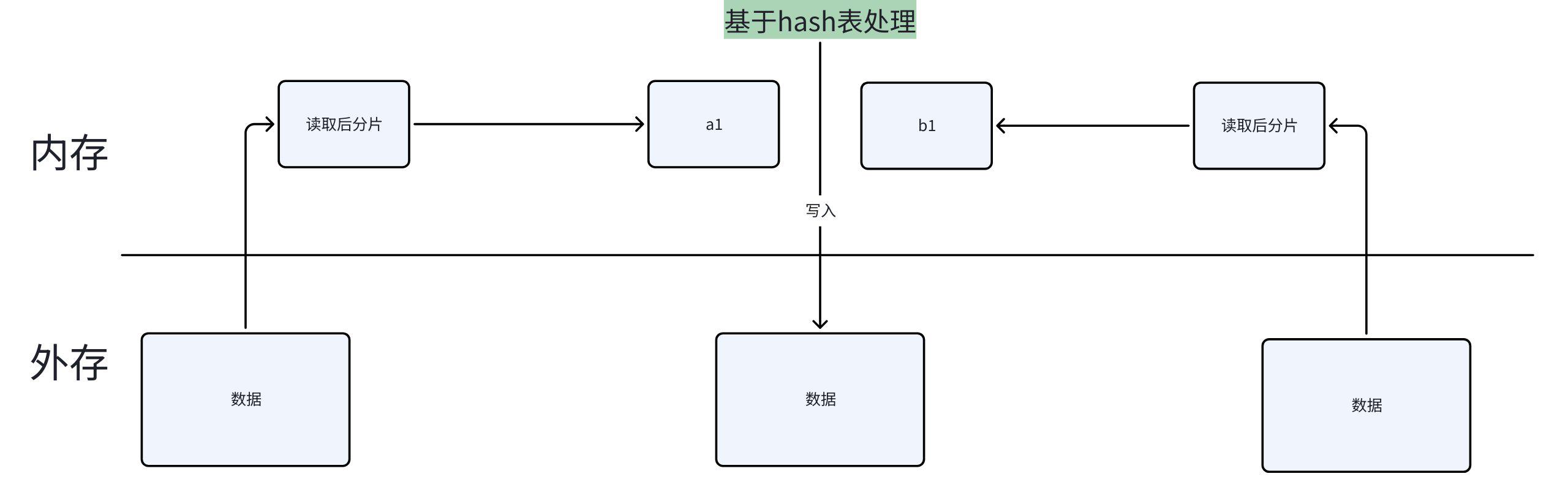
java
int K = 2000; // 分成 2000 个小文件
// 第一步:对 a 和 b 分别做哈希分片
hashPartition("file_a.txt", "a_part_", K);
hashPartition("file_b.txt", "b_part_", K);
// 第二步:逐对分片求交集
for (int i = 0; i < K; i++) {
// 将 a 的第 i 个分片加载到 HashSet
Set<String> setA = loadToSet("a_part_" + i + ".txt");
// 扫描 b 的第 i 个分片,检查是否在 setA 中
BufferedReader readerB = new BufferedReader(
new FileReader("b_part_" + i + ".txt"));
String line;
while ((line = readerB.readLine()) != null) {
if (setA.contains(line)) {
resultWriter.write(line);
resultWriter.newLine();
}
}
setA.clear(); // 释放内存,处理下一对
}为什么分 2000 片?
- 50 亿 x 64 字节 = 320GB
- 320GB / 2000 = 160MB / 片
- HashSet 有额外开销(约 3-4 倍),160MB x 4 ≈ 640MB
- 4GB 内存完全够用
核心思想:Hash 分片的目的就是让每对分片的数据量小到内存可以放得下,然后逐对比较。
解题通用套路总结
到这里,我们已经覆盖了海量数据处理的主要题型。结合前面几篇的排序、TopK、频率统计,汇总成一张完整的表:
| 题型 | 核心数据结构 | 处理策略 |
|---|---|---|
| 存在性查询 | 哈希表 / 位图 / 布隆过滤器 | 内存够用哈希表,不够用位图 |
| 去重 | 哈希表 / 排序 | Hash 分片 + 逐片去重 |
| 找重(求交集) | 哈希表 / 排序 + 双指针 | Hash 分片 + 逐片求交 |
| TopK | 小顶堆 | 流式处理或分片后合并 |
| 频率统计 | 哈希表 + 小顶堆 | Hash 分片 + 逐片统计 + 汇总 |
| 排序 | 归并排序 / 桶排序 | 外部排序 + 多路归并 |
万能思考框架
不管遇到什么海量数据题,按这个顺序思考:
第一步:内存放得下吗?
如果放得下,直接用内存数据结构(HashMap、HashSet、堆)解决,没什么好说的。
第二步:放不下 → 哈希分片 → 分而治之
这是 90% 海量数据题的核心套路。把大文件按 hash 拆成小文件,每个小文件能放进内存,然后逐片处理。
第三步:考虑优化
- 多线程:多个分片可以并行处理,但要注意 IO 瓶颈和 GC 问题
- 分布式(MapReduce):每个分片交给不同机器处理,天然适合 Map-Reduce 框架
面试答题路径:
分析数据量 → 估算内存 → 选择分片策略 → 选择核心数据结构 → 描述处理流程面试要点
答题模板:先分析数据量和内存限制 → 选择分片策略 → 选择核心数据结构 → 描述处理流程。面试官要的不是代码,而是你的系统性思维。
位图和布隆过滤器是高频考点:面试官经常追问「BitSet 的原理」「布隆过滤器为什么会误判」「误判率怎么计算」。建议深入理解,而不仅仅是知道名字。
Hash 分片是万能钥匙:去重、找重、频率统计、排序——几乎所有「内存放不下」的问题,第一反应就是 Hash 分片。记住这个套路,面试时就不会慌。
主动算数:面试时算一下内存和分片数,比如「50 亿条 URL,每条 64 字节,总共 320GB,分 2000 片,每片 160MB,加上 HashSet 的额外开销大约 640MB,4GB 内存足够」——这种回答比泛泛而谈"用 hash 分片"有说服力得多。
注意边界情况:
- 分片后某个片特别大(数据倾斜)→ 对该片再次分片
- 布隆过滤器的误判 → 需要二次确认机制
- 外部排序时的磁盘 IO 优化 → 缓冲区大小的选择