DS 67 个知识点该各出多少道巩固题——codebrick 是怎么算出来的
DS 67 个知识点摊到 233 道真题上,每个 KP 该补多少道巩固题? 把题目和知识点的关系建成二分图算度,再用条件概率交叉一遍难度,每个 KP 得到一个二维坐标(频数、高难占比)。 在这个坐标里跑 K-Means 自动分档,跟手工分档比一致率 47%。剩下 53% 的差异由大纲先验和学生易错先验补回来 —— 对应贝叶斯里的似然 × 先验 = 后验。 最后落到一张 551 道总配额表上:avl 配 16 道、bubble-sort 配 4 道,都是从这套推导链推出来的,不是拍脑袋。
1. 问题:「这个知识点出多少题」不能靠拍脑袋
codebrick 要给 DS 67 个知识点 (KP) 出一批巩固题,把题量配额定下来。最朴素的做法是:
「难,多出点」「 简单,少出点」
听上去合理,但说不清楚「多多少 / 少多少 / 凭什么是这个数」。一旦学生群里有人问「你凭什么给 avl 出 16 道」,「我觉得」三个字撑不住。
所以这件事必须落到数据上。要回答的具体问题是:
- DS 67 KP 在 233 道真题里到底怎么分布的?
- 哪些 KP 不仅常考、而且考得难?
- 不同档位的 KP 应该补多少巩固题,才既够用又不浪费?
下面这篇文章会把这条决策链拆开走一遍。每一步带代码、带数学、带数据,最后落到一张表上——DS 67 KP 各应该出多少道巩固题。
2. 数学背景:题目↔知识点是一张二分图
第一步要弄清楚「题目」和「知识点」是什么关系。
一道真题可以挂多个 KP,一个 KP 也会出现在多道题里。举两个具体例子(数据快照 2026-05-22):
- 真题
ds-2023-06同时挂 BFS + prim + kruskal - KP
binary-tree-basics出现在 21 道真题里
这正是离散数学里的二分图 (Bipartite Graph):
其中:
= 233 道题节点(query node) = 67 个 KP 节点(knowledge point node) = 题↔KP 挂接边 - 没有
内部的边,也没有 内部的边
每个 KP 节点的度 (degree) 就是「这个 KP 在多少道真题里出现过」:
二分图典型应用是推荐系统(用户↔商品)和生物网络(疾病↔基因)。「题目↔知识点」是个教育数据视角的标准二分图建模。
把它当二分图的好处:算 KP 真题数不需要嵌套循环。哈希一遍边集就够:
from collections import Counter
# 把 DataFrame 转成边集
edges = []
for _, row in df_q.iterrows():
q_id = row["slug"]
for kp in (row.get("topics") or []):
edges.append((q_id, kp))
# O(|E|) 聚合
kp_freq = Counter(kp for _, kp in edges)这是工程里再普通不过的「哈希聚合替代暴力嵌套」。具体到本数据:暴力嵌套是
这跟 408 数据结构里 KMP 用失败函数避免暴力回退是同一思想:用空间换时间,用预处理换查询效率。
3. 数据来源
| 字段 | 值 |
|---|---|
| 数据快照日期 | 2026-05-22 |
| 数据源 | codebrick 题库 DS 真题集 |
| 真题总数 | 233 道(2009-2026,18 个年份) |
| KP 字典版本 | v1(2026-05-04 落定,189 KP / 26 章,DS 子集 67 KP) |
| 难度分布 | d=1: 4 / d=2: 39 / d=3: 101 / d=4: 85 / d=5: 4 |
| 高难占比(d≥4) | 38.2% |
所有元数据都来自每道真题 md 文件头部的 YAML frontmatter(topics、difficulty、year 等),由独立脚本 extract_metadata.py 解析出来落到 JSON 快照里。快照带日期,谁哪天跑的就用谁的版本,不会动态变。
完整代码 + 数据快照 + notebook 都在 GitHub 仓库 408-data-insights(链接发布时补充),所有代码片段都直接从 notebook 复制过来,没改一个字。
4. 分析过程
4.1 算每个 KP 的频数
哈希聚合一遍 + 排序:
df_kp = (
pd.DataFrame(kp_freq.items(), columns=["kp_id", "freq"])
.sort_values("freq", ascending=False)
.reset_index(drop=True)
)
print(f"覆盖到的 KP 数: {len(df_kp)}/67")
print(f"未被任何真题挂的 KP 数: {67 - len(df_kp)}")
df_kp.head(20)跑出来 57 个 KP 被真题覆盖,10 个 KP 字典有但真题没考过(floyd / red-black-tree / cross-list / static-linked-list / union-find / queue-application / linked-stack / string-pattern-matching / binary-insertion-sort 等)。Top 11 的 KP:
| 排名 | KP | 真题数 |
|---|---|---|
| 1 | binary-tree-basics | 21 |
| 2 | graph-concepts | 19 |
| 3 | huffman | 14 |
| 4 | stack-application | 12 |
| 5 | general-tree | 11 |
| 5 | b-tree | 11 |
| 7 | topological-sort | 10 |
| 8 | sequential-list | 9 |
| 8 | avl | 9 |
| 10 | singly-linked-list | 8 |
| 10 | bst | 8 |
Top 11 KP 加起来 130 道题,占 233 道真题的 56%。剩下 56 个 KP 分剩下 44% 真题。典型的长尾。
这一步还没回答「avl 该出多少题」,只回答「avl 在真题里出现 9 次」。下一步要看难度。
4.2 加上条件概率:高难占比
「真题多」不等于「需要补题多」。如果一个 KP 全是送分概念题,刷再多遍意义不大。真正需要补给的,是学过了还是会错的那种 KP。
形式化地,定义「KP 高难占比」是给定题目属于
实现起来就是把 df_q 筛一遍再哈希聚合一次:
df_q["difficulty"] = df_q["difficulty"].astype(int)
df_hard = df_q[df_q["difficulty"] >= 4]
hard_edges = [(q.slug, kp) for _, q in df_hard.iterrows() for kp in (q.topics or [])]
kp_hard_freq = Counter(kp for _, kp in hard_edges)
df_kp["hard_count"] = df_kp["kp_id"].map(kp_hard_freq).fillna(0).astype(int)
df_kp["hard_ratio"] = (df_kp["hard_count"] / df_kp["freq"]).round(3)跑完拿到一份「高难占比 ≥ 0.5」的清单。这才是真正的硬骨头:
| KP | 真题 | d≥4 | hard_ratio |
|---|---|---|---|
| critical-path | 6 | 6 | 1.00 |
| inorder | 5 | 4 | 0.80 |
| dijkstra | 5 | 4 | 0.80 |
| avl | 9 | 7 | 0.78 |
| sequential-list | 9 | 6 | 0.67 |
| b-tree | 11 | 7 | 0.64 |
| shell-sort | 5 | 3 | 0.60 |
| general-tree | 11 | 6 | 0.55 |
| singly-linked-list | 8 | 4 | 0.50 |
| hash-open-addressing | 6 | 3 | 0.50 |
avl 在这张表上的位置说明了一切:真题 9 道里 7 道是 d≥4。意味着这个 KP 不仅常考,而且只要考就是难题。这就是 codebrick 必须给它配厚补给的硬证据。
对比一下 bubble-sort:真题数 1 道,hard_ratio = 0.0(这唯一一道是 d=3 的中档选择题,散点图里在最左下角)。这个差距不是「感觉上 avl 更难」,是数据上 avl 的硬骨头属性比 bubble-sort 强了一个数量级。
4.3 散点图:两个维度一次性看完
把每个 KP 当成一个二维点
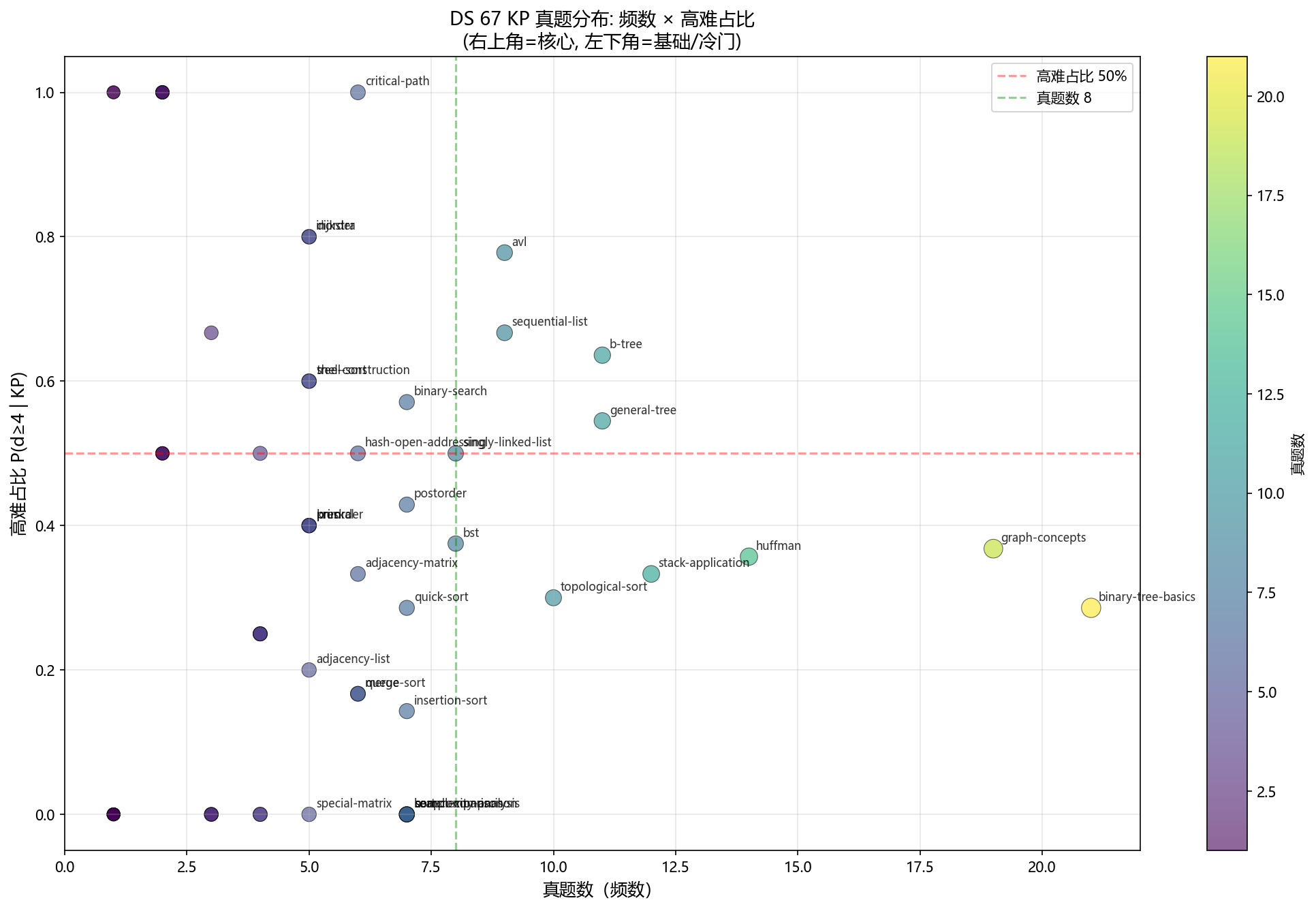
读图四个象限:
- 右上角(高频高难):核心 KP,必给厚补给。avl / general-tree / b-tree / dijkstra 都在这块
- 左上角(低频高难):题量真空 + 必考冷门,每多出 1 道边际价值最高。critical-path / shell-sort 在这块
- 右下角(高频低难):套路题型,巩固题量少即可。sort-comparison / search-comparison / complexity-analysis 在这块
- 左下角(低频低难):基础 / 冷门 KP,4-6 道建立题感就行
红色虚线是高难占比 50% 阈值,绿色虚线是真题数 8 阈值。两根线把图切成 4 个区。每个区对应一种产品决策:
| 象限 | 区域含义 | 产品动作 |
|---|---|---|
| 右上 | 核心 KP | 单 KP 12-17 道,含 3-5 道大题 |
| 左上 | 题量真空 + 必考 | 单 KP 5-8 道选择题,可含 1 道大题 |
| 右下 | 套路题型 | 单 KP 4-7 道,纯选择题,不出大题 |
| 左下 | 基础/冷门 | 单 KP 2-6 道选择题 |
这张图是后面所有配额的视觉证据。任何人问「凭什么 avl 给 16 道」,答案就是「avl 的散点位置在 (9, 0.78),右上角硬核心区」。
4.4 线性代数视角:加权评分把两个维度压成一个数
散点图直观,但落到「配多少道题」需要一个标量分数。
把每个 KP 的二维特征做 min-max 归一化(让 freq 和 hard_ratio 都落在
然后跟一个权重向量
权重为什么是 (0.6, 0.4) 而不是 (0.5, 0.5)?因为「常考」比「难考」对学生备考的影响更大——学生时间有限的时候优先要把常考的 KP 都覆盖到。这是个先验,由人定,不是数据告诉的。
实现就是一行矩阵-向量乘法:
df_kp["freq_norm"] = (df_kp["freq"] - df_kp["freq"].min()) / (df_kp["freq"].max() - df_kp["freq"].min())
w = np.array([0.6, 0.4])
X = df_kp[["freq_norm", "hard_ratio"]].values # shape (57, 2)
df_kp["score"] = X @ w # 矩阵-向量乘法X @ w 在数学上就是
4.5 K-Means 自动分档跟手工分档差多少?
数据本身的故事到这里讲完了。产品决策还差一步:分档。「核心 / 重要 / 基础 / 冷门」这 4 档不是数据告诉的,是按大纲和教学经验手工切的。
那么问题:手工分档是不是凭感觉? 验证方式就是跑一遍 K-Means,让算法自己在 (freq, hard_ratio) 平面上找 4 类,看跟手工分档差多少。
K-Means 的目标函数:
找 4 个聚类中心
from sklearn.cluster import KMeans
from sklearn.preprocessing import StandardScaler
# K-Means 对量纲敏感,先 standardize(均值 0 方差 1)
scaler = StandardScaler()
X_scaled = scaler.fit_transform(df_kp[["freq", "hard_ratio"]].values)
kmeans = KMeans(n_clusters=4, random_state=42, n_init=10)
df_kp["cluster"] = kmeans.fit_predict(X_scaled)
# 按平均 freq 把 cluster 排序映射到「核心/重要/基础/冷门」
cluster_avg_freq = df_kp.groupby("cluster")["freq"].mean().sort_values(ascending=False)
cluster_to_tier = {c: i for i, c in enumerate(cluster_avg_freq.index)}跑完得到的对照表:
| 档位 | K-Means 自动 | 手工分档 |
|---|---|---|
| 🔴 核心 | 7 | 13 |
| 🟡 重要 | 19 | 25 |
| 🟢 基础 | 22 | 19 |
| ⚪ 冷门 | 9 | 10 |
| 合计 | 57 | 67 |
**注:K-Means 只对被真题覆盖的 57 个 KP 跑,剩下 10 个 0 真题的 KP 不进入聚类(没有 freq 没法算),手工分档则把它们补到「⚪ 冷门」档。这是两边总数差 10 的原因。
最终一致率 47.4%(27/57 个 KP 自动和手工档位完全一样)。
47% 不算高。但具体看哪 53% 不一致,会发现这部分差异是有原因的——下一节展开。
4.6 那 53% 不一致:数据少了一个维度
把不一致的 KP 拿出来看,分两类:
手工提档:自动判定偏低,被升上去
kmp-algorithm:freq=3,数据上看是普通 KP;但大纲明确必考,学生群里公认难。提到核心tree-construction:自动「重要」;但「由遍历序列构造二叉树」每年应用题挂着,跟 preorder/inorder 联动很深。提到核心
手工降档:自动判定偏高,被压下去
graph-concepts:freq=19 数据上看是核心;但题型偏概念辨析(度、路径长度、连通性这些),不是计算密集型,单 KP 不需要那么多巩固题。降到重要sequential-list:freq=9, hard_ratio=0.67,自动判核心;但顺序表是入门必学概念,学生在这上面翻车的比例其实不高,降到重要
53% 不一致的来源清楚——K-Means 只看了二维数值 (freq, hard_ratio),手工分档多看了大纲必考度和学生易错记录这两个维度。大纲必考度来自 408 官方考试大纲,学生易错记录目前是整理 233 道真题时积累的手工经验值,后续 codebrick 主站 WA 分布数据成熟后会用真实答题错率反推校准。
写成贝叶斯的语言:
K-Means 是纯频率主义视角,只算似然,丢掉了先验。把先验加回来才是后验。
所以 47% 的一致率不是 K-Means 失败,是它本就只能告诉你「数据怎么说」这一半;剩下一半得靠领域知识自己补。任何只贴 K-Means 结果不补先验的分档表都是欠工的。
5. 结论 + 决策映射
把 § 4 的所有步骤合在一起得到的最终配额表:
| 档位 | KP 数 | 单 KP 选择题 | 单 KP 大题 | 选择题小计 | 大题小计 | 合计 |
|---|---|---|---|---|---|---|
| 🔴 核心 | 13 | 13.6 | 2.9 | 177 | 38 | 215 |
| 🟡 重要 | 25 | 7.4 | 0.9 | 184 | 22 | 206 |
| 🟢 基础 | 19 | 3.8 | 0 | 73 | 0 | 73 |
| ⚪ 冷门 | 10 | 5.6 | 0.1 | 56 | 1 | 57 |
| 合计 | 67 | — | — | 490 | 61 | 551 |
DS 巩固题总配额 551 道(490 道选择题 + 61 道大题)。
回到开头那个问题——「为什么 avl 16 道,bubble-sort 4 道」?
- avl 位于核心档(freq=9, hard_ratio=0.78,散点图右上角),按核心 KP 13.6 道选择题 + 2.9 道大题的配额,约 16-17 道
- bubble-sort 位于基础档(freq=1, hard_ratio≈0.0,散点图左下角),按基础 KP 3.8 道选择题 + 0 道大题的配额,约 4 道
差出来的 12 道不是拍脑袋。是 233 道真题、67 个 KP、5 个数学 / CS 理论一起算出来的。
6. 自己跑一遍
完整代码 + 数据快照 + notebook 都在 GitHub 仓库 408-data-insights(链接发布时补充)。
复现步骤(VS Code 用户推荐):
pip install -r requirements.txt
python scripts\extract_metadata.py --subject ds # 生成最新数据快照
# 在 VS Code 打开 notebooks\01-ds-kp-distribution.py
# 每段 # %% 上方有 Run Cell 按钮,跟 Jupyter 一致跑完会拿到:
data/ds-real-exam-snapshot-YYYY-MM-DD.json—— 真题元数据快照reports/ds-kp-scatter-YYYY-MM-DD.png—— 本文那张散点图- 每段代码的中间表(频数、高难占比、K-Means、配额表)
主要依赖:pandas / numpy / scikit-learn / matplotlib,都是标准数据科学栈,已写在 requirements.txt 里。
写在最后
完整推导链路:
二分图建模 → 哈希聚合算 freq → 条件概率算 hard_ratio → 散点图 + min-max 归一化 → 向量内积加权评分 → K-Means 自动分档 → 贝叶斯先验补充 → 最终 4 档配额表
每一步都能在 notebook 里跑一遍验证。如果跑出来跟本文数字对不上,要么是数据快照日期不同(真题在更新),要么是 K-Means 的 random_state 不同(聚类边界点会跳)。两者都正常,结论方向不变。
下一篇计划讲「26 章 × 难度热图——408 命题组的偏好画像」,用同一套数据、不同的分析视角,会用到统计学里的描述统计和信息论里的熵。
关联文章(规划中):
- 02 · 26 章 × 难度热图:408 命题组的偏好画像
- 03 · 2009-2026 命题轨迹的时间序列建模
- 04 · KP 共现网络:哪些知识点是「必考组合」
数据快照日期:2026-05-22 · 文章版本:v1.1