一夜单 IP 35712 个请求 —— 用 408 知识给独立站做三层反爬
2026-05-09 晚上,主站公网带宽利用率打到 525%,35712 次请求来自同一个 IP,UA 88% 是开源工具
website-scraper。整趟排查 + 反爬只用了 11 个 408 大纲内的知识点:标准端口、TCP 握手、文件系统、哈希表 GROUP BY、排序、KMP、哈希表 O(1) 查找、多模式串 / DFA、漏桶限速、信号量、HTTP 状态码。每个知识点都在 codebrick 上配有可视化页面,下文里以超链接直达。
1. 事件全貌:三张图把现场拉出来
三个监控视角同时发出信号。
百度统计:日 PV 一柱独高
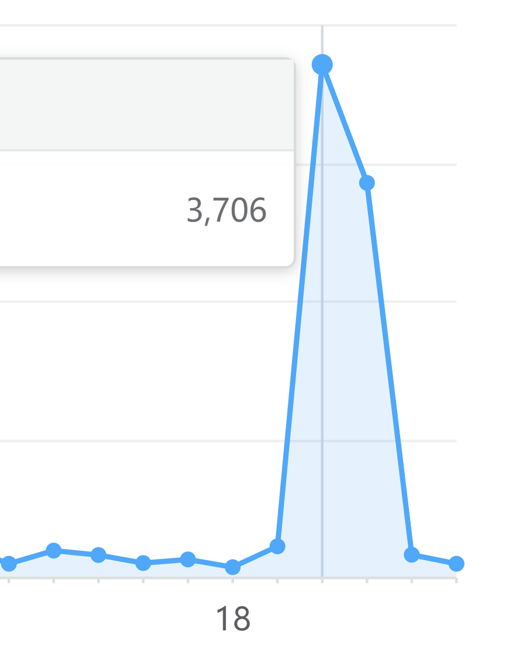
事件当天日,小时 PV 突然飙到 3,706。后台按 IP 下钻,单一 IP 112.117.194.xx 贡献绝大部分,剩下的零碎流量也大量集中在同一 IP 的不同 UA 上。
阿里云:公网流出带宽打满
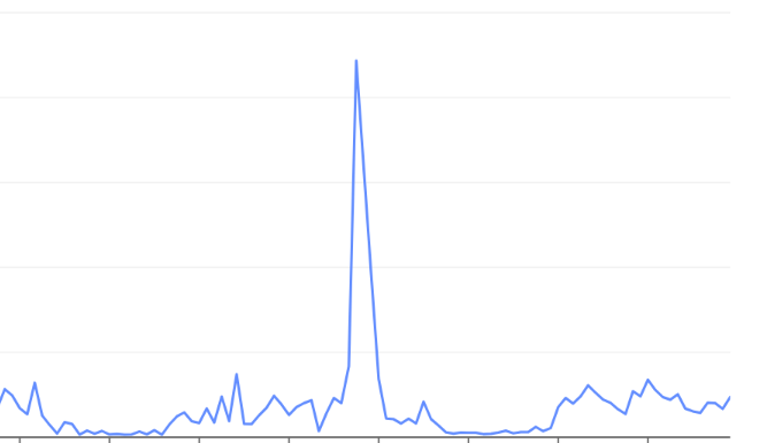
同一时段阿里云监控里公网流出带宽利用率峰值打到 525%,网络套餐被打爆。CPU 同时段只有 0.2% —— 说明请求都落在静态资源(HTML / 图片 / JS bundle),不是计算密集型攻击,是大批量下载。
Nginx 访问日志:UA 分布
35712 website-scraper (https://github.com/website-scraper/node-website-scraper)
3512 node-fetch
589 HeadlessChrome/148
36 com.apple.WebKit Version/26.0
17 curl/8.16.0
1 Google-Gemini-CLI单 IP 累计 35712 次请求,88% 来自开源扒站工具 website-scraper,同一 IP 还混着 Safari、curl、Gemini CLI 这种真人交互工具 —— 行为指纹清楚:背后一个真人在系统性扒站。工具中性,意图未知,重心放在「怎么应对」。
2. 第一步:SSH 上服务器
用到的 408 知识点 ① CN 应用层 · 标准端口表(22 SSH / 80 HTTP / 443 HTTPS / 53 DNS) ② CN 传输层 · TCP 三次握手
ssh root@codebrick.tech回车之后底层走两件事:先做 TCP 三次握手(SYN → SYN+ACK → ACK)建连,再进入 SSH 自己的加密协商。SSH 默认走 22 端口,这是 CN 应用层那张「熟知端口」表里 408 年年考的固定项。
3. 第二步:找主站日志
用到的 408 知识点 ③ OS 文件系统 · 目录组织
进了服务器要找的是主站访问日志。最稳的做法是直接到 nginx 站点配置里反查 access_log 指令,路径一目了然:
grep access_log /www/server/panel/vhost/nginx/*.conf
# → access_log /www/wwwlogs/codebrick.tech.log;
ls -lh /www/wwwlogs/codebrick.tech.log
# → 159MOS 文件系统那一章讲过:目录按职责组织,不同应用日志路径并不统一,反查配置文件最准。159MB 日志,肉眼看不动,下一步交给文本工具。
4. 第三步:awk 一行找出 top IP
用到的 408 知识点 ④ DS 哈希表 · GROUP BY(拉链法) ⑤ DS 排序 · 快速排序
159MB 日志怎么找出真凶?一行 awk:
LOG=/www/wwwlogs/codebrick.tech.log
awk '{a[$1]++} END {for (i in a) print a[i], i}' $LOG \
| sort -rn | head -10拆开看:
a[$1]++:把每行日志第 1 列(IP)当哈希表的 key,命中次数累加成 value。这就是 DS 哈希表那一章的「GROUP BY」—— 一次扫描,O(|E|) 完成聚合,不需要嵌套循环sort -rn:按 value 倒排,外排序与快排同思想,让最高频的 IP 浮到顶部
跑完结果 Top 1:
35712 112.117.194.xx
...单 IP 35712 次请求,占当时总流量 87%。这个量级不是真人能干出来的。
⚙️ 工程小延伸:哈希聚合替代暴力嵌套,跟 KMP 用 next 数组避免暴力回退是同一思想 —— 用预处理换查询效率。日常工程里再普通不过。
5. 第四步:UA 拆解,确认工具指纹
用到的 408 知识点 ⑥ DS 字符串匹配 · KMP / DFA 自动机
IP 锁定后,再看它用什么工具。UA(User-Agent)是 HTTP 请求头里的字符串字段:
grep '112.117.194.xx' $LOG \
| awk -F'"' '{a[$6]++} END {for (i in a) printf "%6d %s\n", a[i], i}' \
| sort -rn | head -10输出回到 § 1 那张 UA 分布表。88% 是 website-scraper 这个工具的特征字符串。
下一步 Nginx 要在线识别这种字符串模式 —— Nginx 配置写正则,正则引擎本质就是 DS 字符串匹配那一章的有限自动机,KMP 的 next 数组是这种自动机最简版本。多个 UA 特征用 | 分隔,编译后会合并成一个 DFA,每个请求过一遍就完事。
6. 第五步:三层反爬上线
用到的 408 知识点 ⑦ DS 哈希表 · O(1) 查找(开放定址) ⑧ DS 字符串 · 多模式匹配 / DFA ⑨ CN 流量控制 · 漏桶 / 滑动窗口 ⑩ OS 同步 · 信号量 / 生产者消费者
事件指纹清楚之后,反爬配置一次到位。三层从外到内依次叠加:
第一层 · IP 黑名单(DS 哈希表 O(1) 查找)
写在站点 server {} 块:
deny 112.117.194.xx;Nginx 启动时把 deny 指令编入 IP 查找结构,每次请求做一次 O(1) 命中检查 —— 几千条黑名单也是常数时间。
短期止血用,长期靠不住:动态 IP 一换就失效。
第二层 · UA 正则黑名单(DS 多模式串 / DFA)
if ($http_user_agent ~* "(website-scraper|node-fetch|HeadlessChrome|PhantomJS|Scrapy|wget)") {
return 403;
}竖线分隔的多个特征串编译为一个 DFA 自动机,每个请求的 UA 过一遍状态机,命中即返 403 Forbidden。这是 KMP 那一章末尾的多模式串思想。
第三层 · 单 IP 限速(CN 流量控制 + OS 信号量)
zone 定义写在主 nginx.conf 的 http {} 块:
limit_req_zone $binary_remote_addr zone=cb_throttle:10m rate=10r/s;
limit_req_status 429;站点 server {} 块里启用:
limit_req zone=cb_throttle burst=20 nodelay;含义:单 IP 平均 10 请求 / 秒,允许瞬时突发 20,超出返 429 Too Many Requests。这是 CN 课本传输层讲过的流量控制思想 —— 传输层是滑动窗口,应用层 Nginx 用的是漏桶 / 令牌桶变体,机制不同但目的一致:让对端的速率匹配本端的处理能力。
⚙️ OS 视角:高并发请求一起来时,限速器内部那个「每秒计数器」是临界资源。多个请求同时改它就乱套了 —— 这就是 OS 信号量 / PV 操作守的事。Nginx 自己处理好了,但概念上的对应必须看见。
reload
nginx -t && nginx -s reload-t 先做语法校验再 reload,零停机。
7. 第六步:验证测试
用到的 408 知识点 ⑪ CN HTTP 协议 · 状态码 200 / 403 / 429
三层上线后用 curl 走一遍验证。下面单条命令在 Windows 10+ / macOS / Linux 都能直接复制粘贴运行(Windows 10 起 curl 已是系统内置)。
爬虫 UA · 期望被第二层 UA 黑名单拦截
curl -I -A "website-scraper/v0" https://www.codebrick.tech/看第一行:HTTP/2 403 → 拦截生效。
浏览器 UA · 期望放行
curl -I -A "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 Chrome/130.0.0.0" https://www.codebrick.tech/看第一行:HTTP/2 200 → 通过。
Windows 用户注意:上面命令在 cmd 里直接
curl就行;在 PowerShell 里需要写curl.exe,因为 PowerShell 把curl别名给了Invoke-WebRequest,参数风格完全不同。-I是 HEAD 请求,只取响应头,所以不需要/dev/null这种 Linux-only 写法。
50 并发 · 期望第三层限速生效
并发部分跟 shell 强相关,两个版本对应不同环境:
bash(Linux / macOS / WSL / Git Bash):
for i in $(seq 1 50); do
curl -s -o /dev/null -w "%{http_code}\n" -A "Mozilla/5.0 ... Chrome/130" https://www.codebrick.tech/ &
done | sort | uniq -c
waitPowerShell 5.1+(Windows 10/11 自带):
$jobs = 1..50 | ForEach-Object {
Start-Job -ScriptBlock {
curl.exe -s -o NUL -w "%{http_code}`n" -A "Mozilla/5.0 ... Chrome/130" https://www.codebrick.tech/
}
}
$jobs | Wait-Job | Receive-Job | Group-Object | Format-Table Count, Name两种环境跑完结果都大致是 45 个 200 + 5 个 429。
200 / 403 / 429 都在 CN 应用层那张状态码表上,408 真题考过好几次:
200 OK:请求成功403 Forbidden:服务端拒绝(拒绝原因不一定告诉客户端)429 Too Many Requests:触发限速
8. 为什么不选「强加密 / 强登录 / 验证码」
这是产品决策,跟 408 无关,但能帮考生理解:技术工具不是越重越好。
| 选项 | 拒绝原因 |
|---|---|
| 内容前端加密 | 砸 SEO —— 搜索引擎爬虫看不到内容就不收录,长尾流量没了 |
| 强登录 / 注册码 | 推广阶段在转化漏斗的每一层都加摩擦,掉的用户比被爬走的内容更值钱 |
| 全站验证码 | 同上 · 砸的是「陌生考研生愿意点开链接」这件事 |
| Headless 检测 | HeadlessChrome 能跑任何前端解密逻辑,技术上挡不住决心攻击者 |
所以三层反爬只锁入口层:IP 黑名单 + UA 黑名单 + 限速。挡的是「爬虫的成本」,不是「真人的访问」。爬虫成本一旦高过收益,就会自然退场。
这一节背后还有一条更深的产品哲学:推广阶段,「摩擦 > 被爬」永远不是个划得来的交易。
9. 知识点回顾墙
整趟排查 + 反爬一次性用到了 11 个 408 大纲内的知识点。点任何一个都直达 codebrick 上的可视化页:
🔵 CN 计算机网络 · 4 个
| # | 知识点 | 工程对应 |
|---|---|---|
| ① | 应用层标准端口 | SSH 走 22 端口 |
| ② | TCP 三次握手 | SSH 建连前的 SYN/SYN+ACK/ACK |
| ⑨ | 流量控制 · 漏桶 | Nginx limit_req 限速 10r/s |
| ⑪ | HTTP 状态码 | 200 / 403 / 429 |
🟢 DS 数据结构 · 5 个
| # | 知识点 | 工程对应 |
|---|---|---|
| ④ | 哈希表 · GROUP BY(拉链法) | awk a[$1]++ 累加 IP 频数 |
| ⑤ | 排序(快排) | sort -rn 取 top IP |
| ⑥ | 字符串匹配 KMP | UA 特征字符串识别 |
| ⑦ | 哈希表 · O(1) 查找(开放定址) | IP 黑名单 deny 命中 |
| ⑧ | 多模式串 / DFA | UA 正则 ~* 编译为状态机 |
🟠 OS 操作系统 · 2 个
| # | 知识点 | 工程对应 |
|---|---|---|
| ③ | 文件系统目录 | grep access_log 反查日志路径 |
| ⑩ | 信号量 / PV 操作 | 限速器内部计数器的并发互斥 |
数据快照:2026-05-09 事件 · 2026-05-16 文章版本 v1.2 关联:CodeBrick 主站 · 真题库 · DS 系列 · 67 KP 真题分布